Synapse Link for Dataverse: Exporting to Delta Lake
Microsoft recently released the ability to configure Synapse Link for Dataverse and use Delta Lake as the export format. As I’ve dived into the Synapse Link for Dataverse feature recently with exporting Dynamics 365 Sales data, I was keen to get hands on with the Delta Lake export option. Delta Lake is a data and transaction storage file format very popular in Lakehouse implementations and is becoming a very popular format that enables decoupling storage with compute. More info here.
Here’s my initial experience and thoughts about it and over the coming weeks I’ll dive a little deeper to see what’s going on under the hood. The official documentation is here.
Process Overview
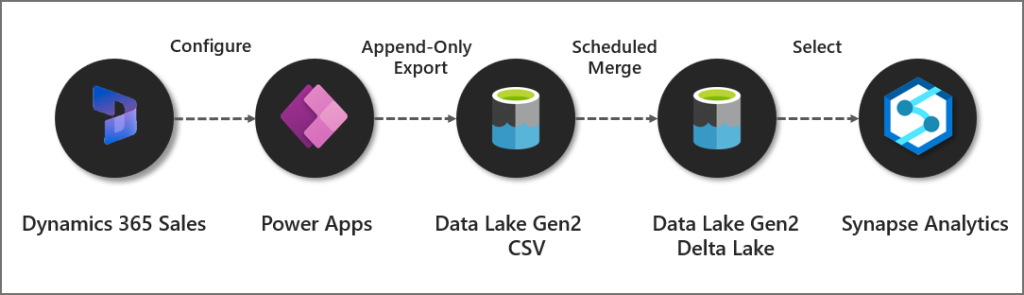
It seems there are quite a few moving parts involved in the process when setting up the sync. This involves the initial configuration in the Power Apps portal to configure the Synapse Link (I cover how to create a Synapse Link in this blog), then data is exported from the Dataverse into the Data Lake in CSV format, then it’s merged into a Delta Lake folder (a folder for each table). The Delta Lake folder is then queryable using Synapse Serverless SQL Pools and Spark pools as tables are created in a Lake Database.
Cost
Let’s raise this first, this feature is chargeable as you need to create a Spark Pool (cluster) within a Synapse Analytics workspace. Now, I’m always keen to identify cost vs value. Something that costs money doesn’t necessarily mean it doesn’t provide value, and vice-verse. But I want to make it clear that this is not a free service as you’ll be charged for the length of time the Spark clusters run when processing and daily maintenance.
I saw a daily cost of £1.23 even though no data had changed in the source Dynamics 365 Sales instance. This cost was due to the daily maintenance that is performed (file compaction and removing of old files) by running a Spark job.
I’ll likely update the blog with any further costs that I encounter, or any recommended practices I find to keep costs to a minimum.
Walkthrough
I’ve covered how to setup Synapse Link for Dataverse in another blog post here, that goes into more detail in terms of setting up a Dynamics environment and permissions required etc. In this blog post I’ll still walkthrough the process, but I’m assuming that Dynamics Sales is already configured, a Synapse Analytics workspace is provisioned, and the user has appropriate permissions.
Setup Spark Pool
The first thing to do is set-up a Spark pool in an Azure Synapse Analytics workspace that will be used in the syncing process.
- Login to the Synapse Analytics workspace
- Click Manage > Apache Spark Pools
- Click New and enter the relevant information
- Make sure in Additional Settings that the Spark version is set to 3.1
- Below is an image of the configuration I used successfully.
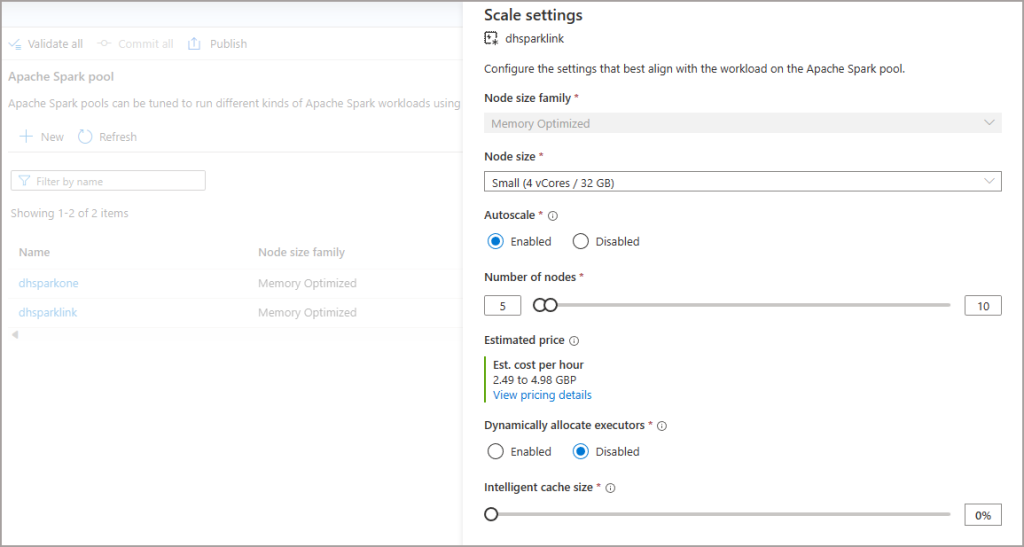
I did encounter an error when I set the number of nodes too low, the Synapse Link process really does want a minimum node number of 5 here.
Synapse Link Configuration
Now that the Spark Pool has been setup, let’s head on over to Power Apps and configure the tables we want to export.
Please note the location of the Synapse Link item may not be immediately available on the left side menu. Hover over Discover then click the Discover all button. You should then see Synapse Link under Data Management, you can then pin the item to the menu.
- Login to Power Apps
- Select the relevant environment from the top-right menu
- On the left menu, select Dataverse -> Azure Synapse Link
- You will need to append ?athena.deltaLake=true to the end of the current URL. E.G. https://make.powerapps.com/environments/<environment_guid>/exporttodatalake?athena.deltaLake=true
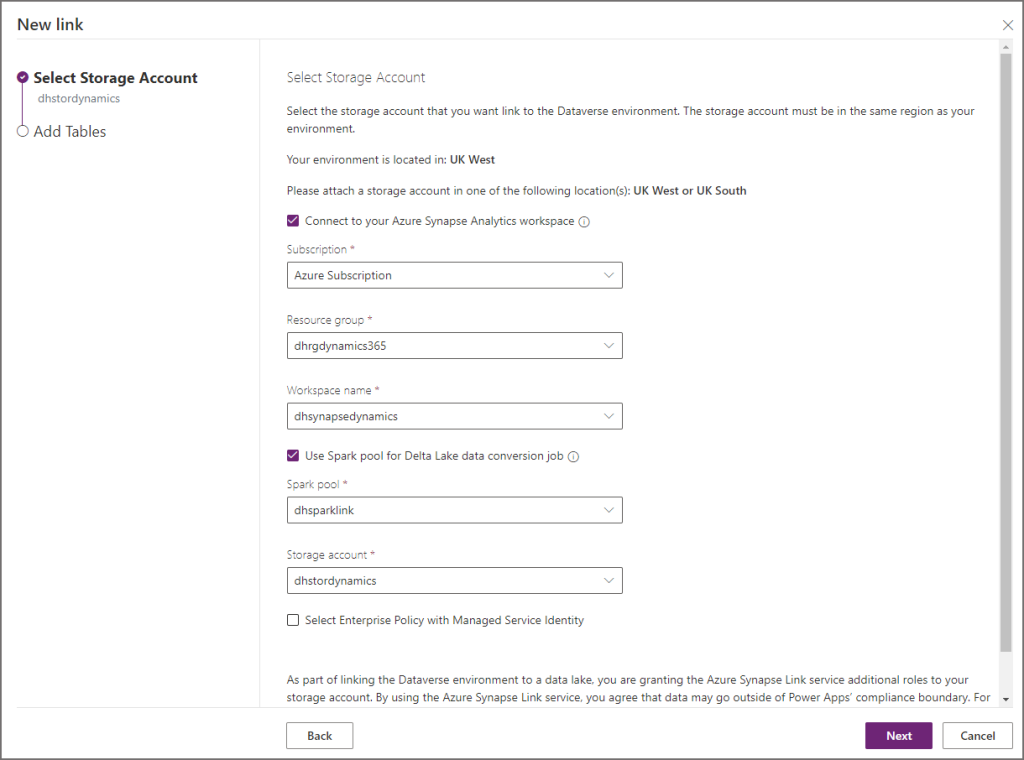
- Click New Link and enter the following information:
- Enable Connect to your Azure Synapse Analytics workspace
- Subscription: Select the appropriate subscription
- Resource group: Select the resource group the Synapse workspace is in
- Workspace Name: Select the specific Synapse workspace
- Enable Use Spark pool for Delta Lake data conversion job
- Then in the Spark Pool drop-down, select the Spark pool created earlier
- Storage account: Select the appropriate storage account to use
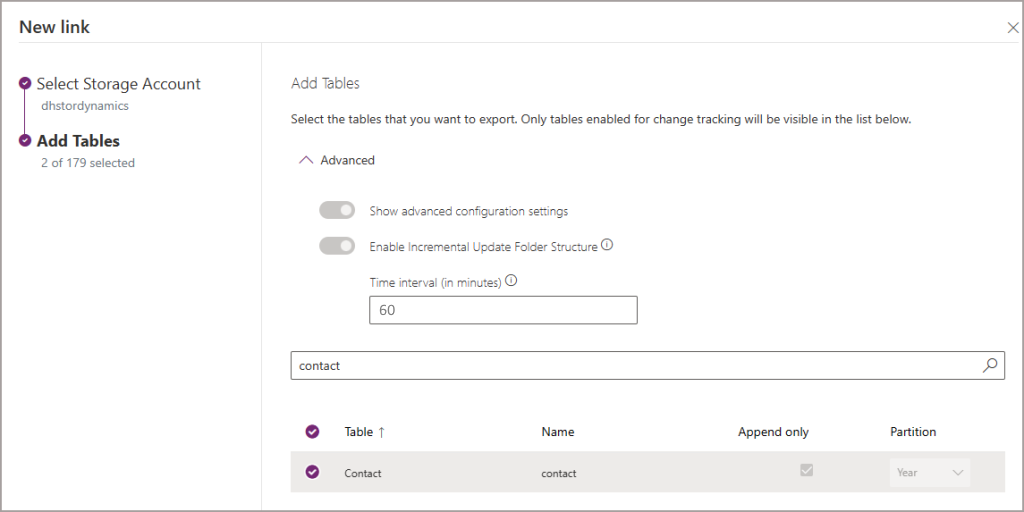
- Click Next and select the tables you want to syncronise.
Note that we cannot configure any of the properties like Append Only, Partition etc. We can configure the Time Interval which will export the data to the data lake within specific folder datetimes (btw this is not a setting to dictate when data is exported to the Data Lake as that is “near real-time”, just the folder structure).
In the configuration below, I’ve set the incremental folder structure time interval to be 60 minutes. This groups up all the changes into folders which are timestamped appropriately (eg the folders will be generated every 60 minutes). As I explained earlier, this has nothing to do with when the data is exported, just the naming of the folders in the data lake.
After the tables have been setup, you’ll see a table showing the sync status.
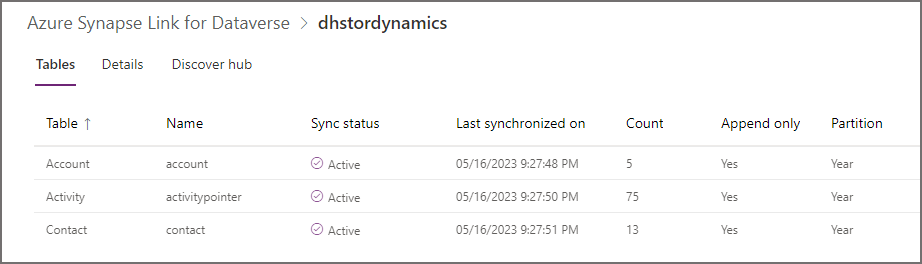
CSV Export
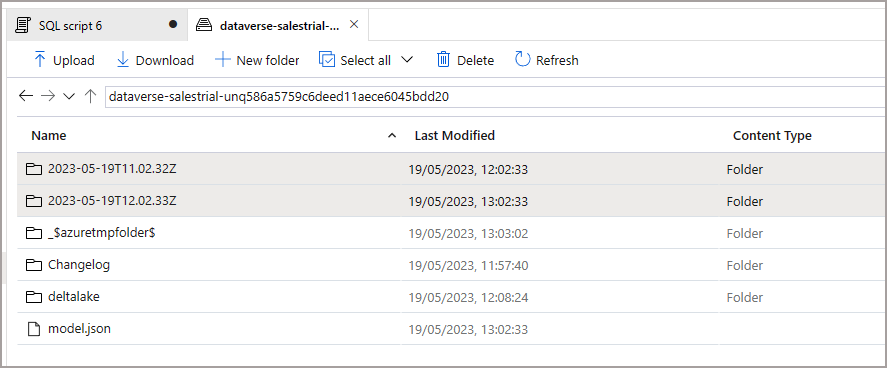
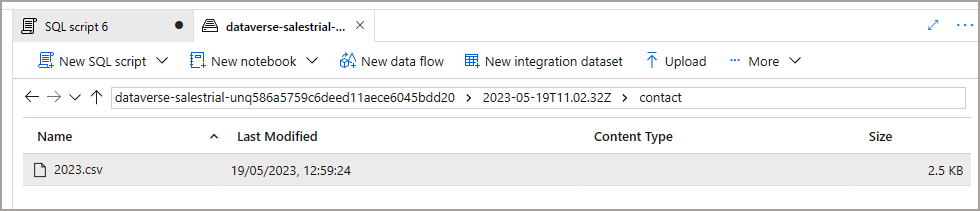
Now if we switch over to the Data Lake storage account that was used when setting up the sync, we see a new container with the Dynamics environment GUID and a set of folders. When data is being exported from the Dataverse into the Data Lake, it will be stored in the datetime folders in CSV format. It’s worth noting now that once the Delta Lake merging process has been completed, the CSV files are removed automatically.
NB: the exported folder structure is timestamped in 60 minute intervals.
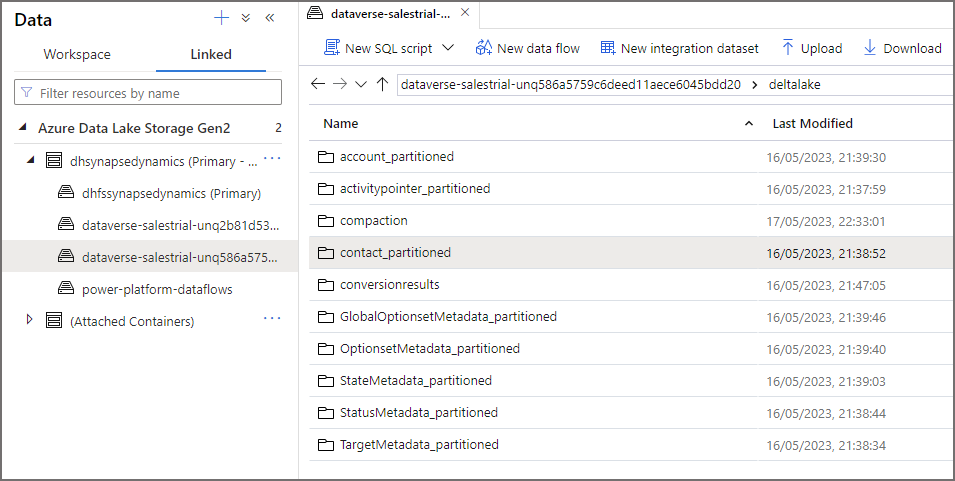
Delta Lake
It takes a few minutes but then in the root container, there will be a folder called deltalake. This contains all the tables that were setup to be synchronised (also includes metadata tables too). Each folder is the table itself and inside each folder will be the parquet files and also the Delta log.
Querying the Delta Lake Tables
Once the Delta Lake folders have been created, we should see a new database in the Lake Database area in Synapse. We can now query the tables using either Serverless SQL Pools or Spark pools. It’s worth noting that querying via Serverless SQL Pools does not allow you to query “point-in-time” as per Delta Lake functionality, you’ll just get the latest version of the data. We can use time-travel in Spark pools though.
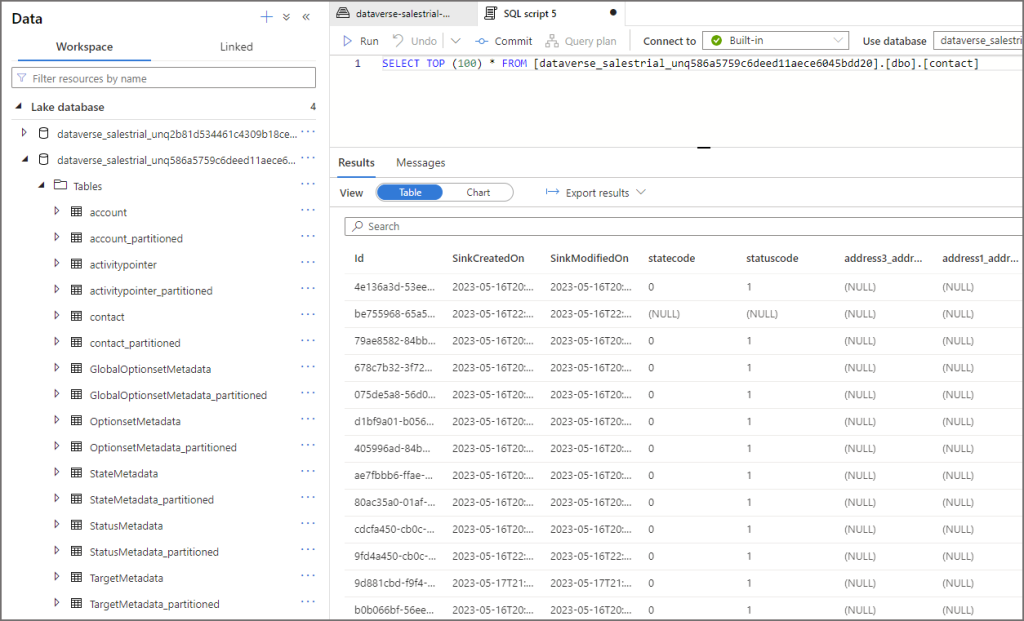
I’ve noticed something confusing with the table names in the Lake database. As per standard process, there will be 2 tables created for each source table. E.G. for the contact table, there will be contact and contact_partitioned (reason in having 2 tables is the base table is near real-time and the partitioned table has a longer update interval to avoid any potential file locking).
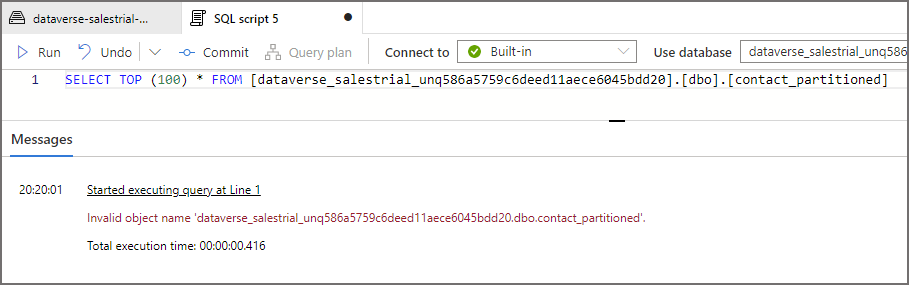
But here, only the contact table can be queried as contact_partitioned generates an error stating it’s an invalid object name.
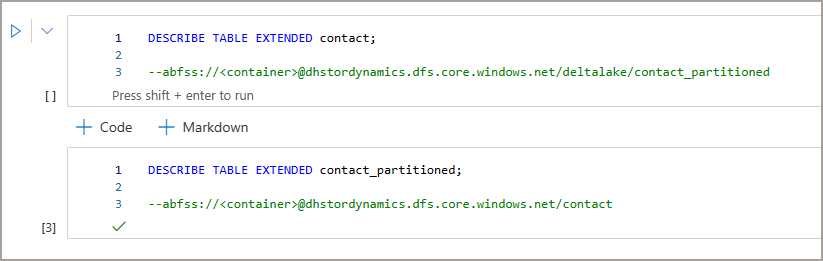
When I look at the table metadata using Spark I can see that the contact table location actually looks at the deltalake\contact_partitioned folder…that’s a little confusing. Also, the data lake location for contact_partitioned which is /contact doesn’t actually exist.
I’ve reached out to Microsoft for clarification on this.
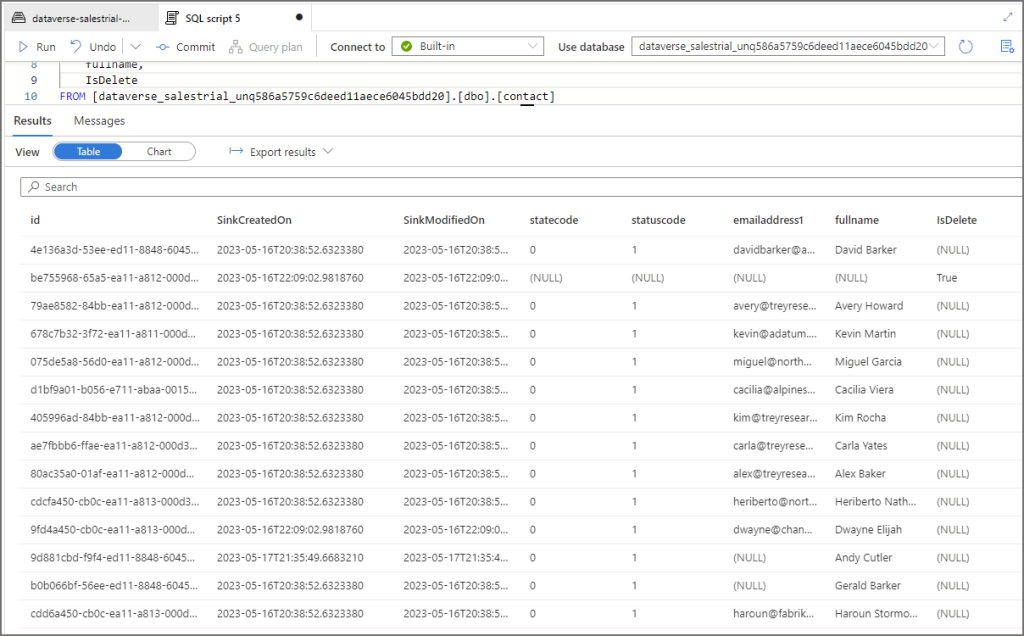
Append Only
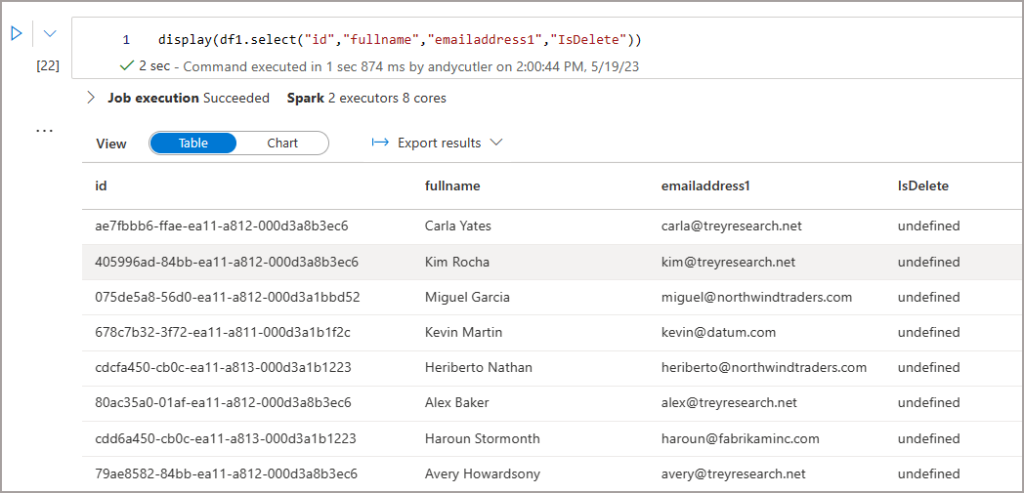
As the sync is automatically configured to use Append-Only, what does that mean? Well, it means the export from Dynamics does not hard-delete any records. If data is deleted or updated in the source, those deletions and updates do not overwrite the destination data in the data lake. E.G. if a record is deleted in Dynamics, then you’ll see True in the IsDelete column.
Time Travel
As I said earlier, Serverless SQL Pools doesn’t have an official way of time-travel in Delta Lake so when querying a Delta folder you’ll always get the latest data. But we are able to use Spark to time-travel in the Dynamics data that’s synced.
df1 = spark.read \
.format("delta") \
.option("timestampAsOf", "2023-05-19 11:09:30.942") \
.load("abfss://<container>@dhstordynamics.dfs.core.windows.net/deltalake/contact_partitioned") \
.show()
Monitoring
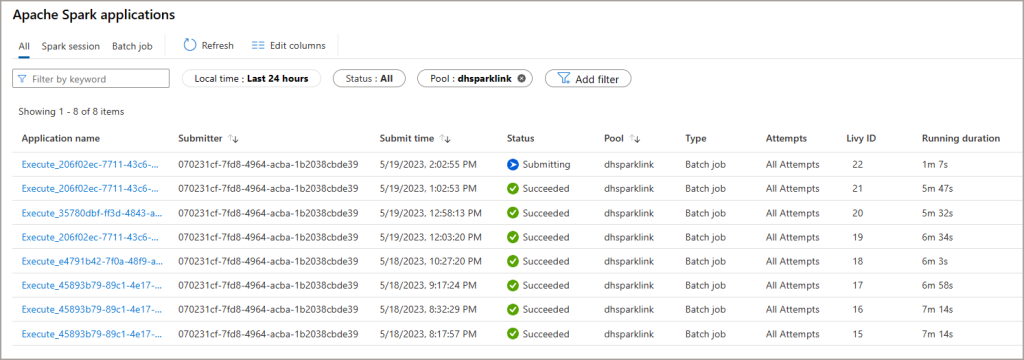
We can monitor the execution of the Spark jobs which perform the merging and also the daily maintenance in the Synapse workspace by clicking Monitor on the main Synapse menu and clicking Apache Spark Applications. This shows when the Spark jobs ran and the duration of the jobs.
Conclusion
It’s a welcome addition to the Synapse Link export options, but at the cost of needing to provision Spark Pools and also a $$$ cost too…this isn’t a free export process so due care needs to be taken with it. The question is, is the cost involved worth being able to automate the export and merging of source Dynamics and Dataverse data into the Delta Lake format? I could not answer that for everyone, again I go back to cost vs value. If this provides value rather than a separate engineered process then great.
I’ll be diving more into this feature over the coming weeks so will keep you updated.
Any questions please reach out here (T)







1 thought on “Synapse Link for Dataverse: Exporting to Delta Lake”
Comments are closed.