Parallel Loading of Tables with Power BI & Azure Synapse Analytics
In this blog I’m continuing my series about using Power BI and Azure Synapse Analytics together and the features between the 2 platforms that are useful. The first blog covered ResultSet Caching in Dedicated SQL Pools so please check that out if you haven’t already. In this blog we’ll be looking at settings within Power BI that can control the parallel loading (executing) of SQL queries on the Synapse SQL Pools. Controlling the number of queries that are sent in parallel to either Dedicated SQL Pools or Serverless SQL Pools can have an effect on loading performance and source system resources. Note that these settings are relevant against any supported data sources, not just Synapse.
We’ll be looking at settings within Power BI that control parallel loading (executing) of SQL queries
For this blog we’ll concentrate on using Dedicated SQL Pools as an example, but the process will be similar for Serverless SQL Pools. Before we get into the parallel options, we need to talk about something first…
Import and DirectQuery
Let’s talk about Import and DirectQuery…this conversation is as old as these connectivity options themselves and no less important here. It doesn’t matter if you’re connecting Power BI to Synapse SQL Pools using either Import, DirectQuery or Dual mode, the parallel/sequential running of SQL from Power BI is relevant. I’ll refer to a slide from my current Power BI + Azure Synapse Analytics session I present at conferences/user groups (a recording will be available soon).

With Dedicated SQL Pools we have the concept of concurrency. At each tier of compute that Dedicated offers there is a set limit on the amount of concurrent queries that can be executed. Here’s an example of the first 6 tiers of compute and the maximum number of queries that can be executed in parallel. Full list here.
| Service Level | Maximum concurrent queries | Min % supported for REQUEST_MIN_RESOURCE_GRANT_PERCENT |
|---|---|---|
| DW100c | 4 | 25% |
| DW200c | 8 | 12.5% |
| DW300c | 12 | 8% |
| DW400c | 16 | 6.25% |
| DW500c | 20 | 5% |
| DW1000c | 32 | 3% |
Dedicated will queue up all requests and execute incoming queries as and when resources become available (and also based on workload management, a very cool feature which I personally love). So as you can see, we have the potential to flood the system with requests if we’re not careful.
In Power BI we can actually set concurrency options for both Import and DirectQuery, this gives us control over how many SQL queries are issued to the source system. Let’s check these settings out and look at the testing results by running a Power BI Dataset refresh which has 6 tables within the model. The model itself is not important, just that we have a model with 6 tables which are sourced from tables in a Dedicated SQL Pool.
Parallel/Sequential Loading Options
In Power BI there are 2 options when looking at parallel loading, we can get to these options in Power BI Desktop by clicking File > Options and Settings > Options.
- Global > Data Load > Parallel Loading of Tables
- Current File > Data Load > Parallel Loading of Tables
However, the Global > Data Load option is for local Power BI Desktop only and is not supported in the Power BI Service. We’ll be looking at the Current File > Data Load as these settings work in both Power BI Desktop and when models are published to the Power BI Service.
Current File
Note that datasets published to Power BI Premium and Premium-Per-User workspaces can benefit from parallelism greater than 6, while datasets in Pro workspaces will not achieve parallelism greater than 6 even when explicitly set. Datasets in Pro workspaces can still be configured for 1 (no parallelism) to 6 parallelism in loading.
Let’s access these options now in PBI Desktop:
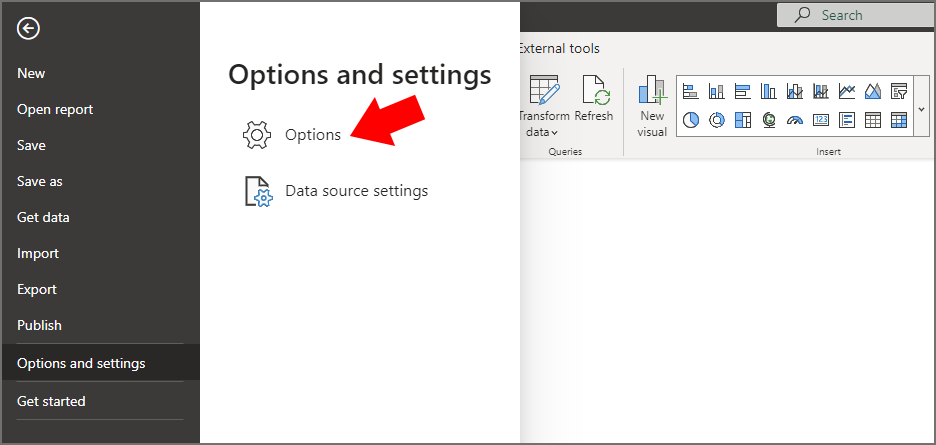
Under the Current File area, click on the Data Load tab. Then scroll down to the Parallel loading of tables section. We now have 3 options we can set.
- Default: Sets the parallelism to the number of cores on the machine running Power BI Desktop (usually in my experience)
- One: Exactly as its name suggests, will only run 1 query at a time
- Custom: Let’s you set the number of parallel executions
In the example below I’ve set the parallel loading of tables to be a maximum of 6.
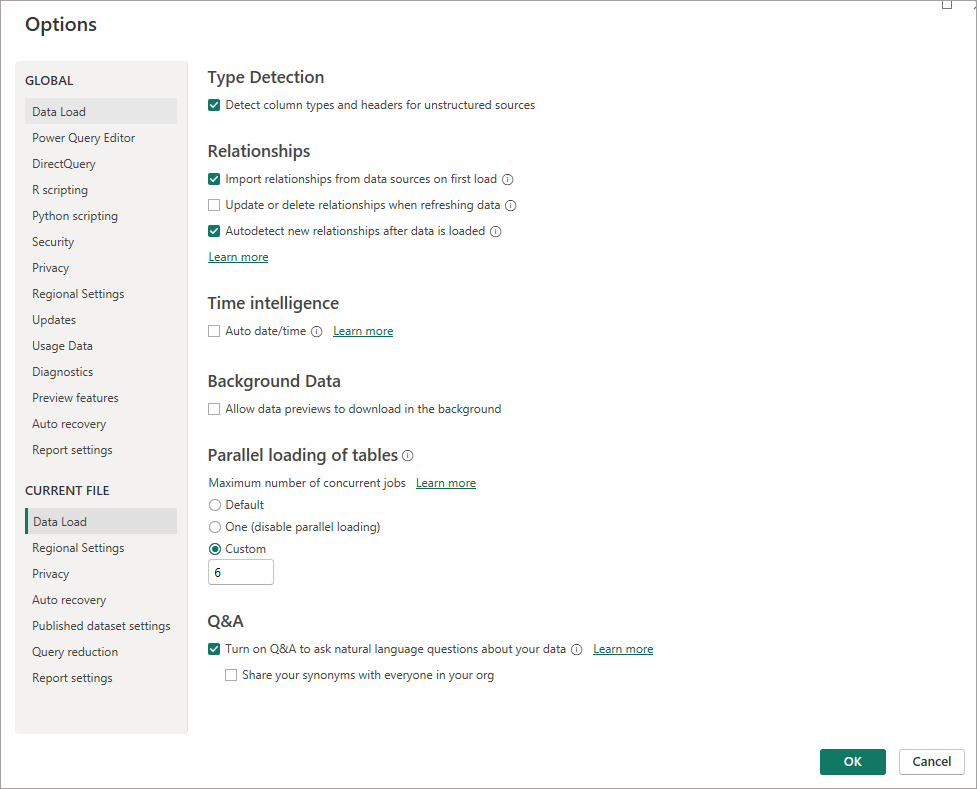
If I now hit refresh on this dataset and jump to looking at the executions within Dedicated SQL Pools we can check what’s happening, I’ll then set the parallel loading of tables to One and check the results too.
Data Load
I’ll be running the query below on the Dedicated SQL Pools database, I’ve used a filter on the command column as the tables that are being loaded are in a “DW” schema – so I can just filter on those tables.
--get requests
SELECT
request_id,
status,
submit_time,
command,
total_elapsed_time,
resource_allocation_percentage,
result_cache_hit
FROM sys.dm_pdw_exec_requests
WHERE command LIKE '%DW%'
ORDER BY submit_time DESC;
As we can see, there are multiple running requests on the Dedicated SQL Pool running in parallel, these will all be taking up system resources (as indicated in the resource_allocation_percentage column), unless the queries are able to use the Dedicated cache.
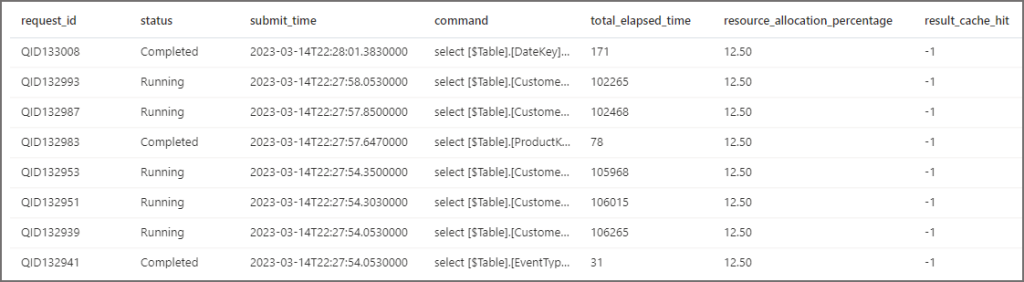
I’ve now gone back to Power BI Desktop and set the parallel loading option to One (disable parallel loading) and set off another PBI dataset refresh. With parallel execution now off, only 1 query is running at a time. The start_time and end_time columns show the contiguous query executions.

DirectQuery
If you find yourself using DirectQuery (through either necessity or by accident…if it’s by accident let’s talk) then you have the option to amend the number of queries run in parallel. This works the same as Import, simply limiting the number of SQL queries sent down to the source data platform. FYI there have been improvements recently in DirectQuery performance, read the MS blog here.
In Power BI Desktop, click File > Options and Settings > Options then click DirectQuery in the CURRENT FILE area. Set an appropriate number.
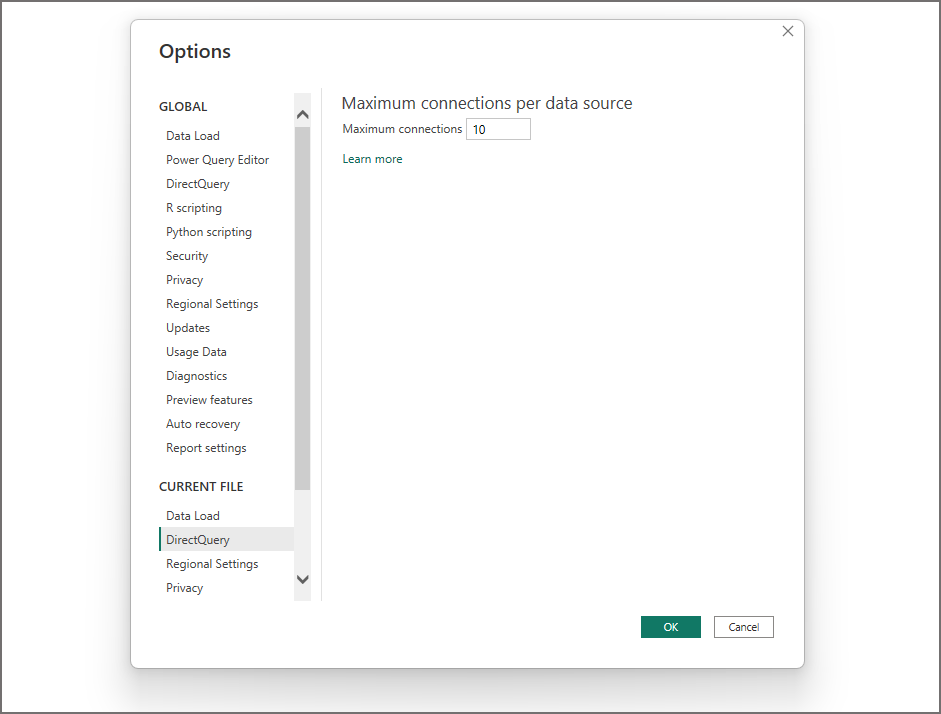
In this example I’ve kept the default of 10 (maximum parallel number in Pro workspaces, 30 for Premium) in a Power BI Dataset with 6 tables all in DirectQuery mode, if I click refresh on the report then Dedicated SQL Pools shows all 6 queries running in parallel. This worked for both the local Desktop file and also when deploying to a PBI service workspace.

I then changed the maximum number to 1 in Power BI Desktop (disabling any parallel execution) and refreshed again. I couldn’t actually see any change in behaviour in Desktop (all queries were executing in parallel) but when deploying to the PBI service the maximum number setting took effect and I could then see queries running serially.

Conclusion
So whether you disable parallel loading or increase/reduce the number of parallel requests is all down to the source system resources available. In terms of Dedicated SQL Pools this will be based on the current DWU tier that is set when the Power BI refresh operations took place. Are there many Power BI datasets that need to be refreshed at the same time and are causing resource contention? Is there a model with a lot of tables loading in parallel and “hogging” all the system resources? These are questions that can answered in each environment.
In terms of Serverless SQL Pools, the documentation states “unlimited concurrency” but in reality concurrency in Serverless will drop as the queries get more complex. Perhaps a reduction in parallel executions will speed up overall dataset refreshes? As always “it depends” and will vary from solution to solution, so test test test!
Thanks for reading and please reach out on Twitter to chat about this.
References
- Evaluation configuration settings for Desktop – Power BI | Microsoft Learn
- Chris Webb’s BI Blog: How The “Maximum Connections Per Data Source” Property On Power BI DirectQuery Datasets Can Affect Report Performance (crossjoin.co.uk)
- Memory and concurrency limits – Azure Synapse Analytics | Microsoft Learn
- DirectQuery in Power BI – Power BI | Microsoft Learn
- https://powerbi.microsoft.com/en-us/blog/query-parallelization-helps-to-boost-power-bi-dataset-performance-in-directquery-mode/






