

Serverless SQL Pools offers a straight-forward method of querying data including CSV, JSON, and Parquet format stored in Azure Storage. A common pattern is to move data from source systems into a data lake and perform data cleansing and transformation, ready for querying. When querying this data using Serverless SQL Pools it’s often useful to define a schema (column names and their associated data types) in a persisted object such as a View or External Table. This View or External Table can then be queried by Data Analysts or used as the source in another application like Power BI.
I’ve been asked questions recently about what happens when source files change schema
What happens if we define a schema over a source folder of conformed files and the schema in a new file in Azure Storage changes? Perhaps a new column was added to the data export process, or columns swapped positions.
In this blog series we’ll look at the impact on Serverless SQL Pools ability to read data when the source files contain different schemas, and look at any behaviours we need to be mindful of. Depending on the file type and options set, undesirable results can be produced which will hugely affect the accuracy of data.


Handling Evolving Schema
This post is not focused on how to handle schema changes, such as new folders in the Data Lake to accommodate files with differing schemas but rather to investigate Serverless SQL Pools behaviour when the schema changes unexpectedly.
Example CSV File
We’ll start with a baseline CSV file of Web Telemetry data containing 10 columns. This file is located in a webtelemetry folder and will be referenced in the BULK option in the OPENROWSET statement.

We’ll be testing using both OPENROWSET Parser versions available when reading CSV data. Version 1 is feature rich however Version 2 has performance improvements but does not support all features of Version 1 (refer to the Arguments section of the OPENROWSET documentation for a list of unsupported features).
PARSER_VERSION = 1.0
We’ll start with Parser Version 1, all the scenarios below produce the same results whether the CSV files have a header row or not as Parser Version 1 defines columns using ordinal position only. We must specify a list of columns in the WITH statement as part of the OPENROWSET command.
If we try the following SELECT with PARSER_VERSION = 1.0, we’ll get an error.
SELECT
UserID,
EventType,
EventDateTime,
ProductID,
[URL]
Device,
SessionViewSeconds,
EventProcessedUtcTime,
PartitionId,
EventEnqueuedUtcTime
FROM
OPENROWSET(
BULK 'https://datalake.dfs.core.windows.net/webtelemetry/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '1.0',
FIELDTERMINATOR = '|' ,
FIRSTROW = 2
) AS r
We must use the WITH statement to define the columns. As stated, Parser Version 1 supports column selection using ordinal positions. We can define this by either ordering the columns in sequence in the WITH statement, or adding the position after the column name in the WITH statement.
In the following example we’ll define the columns by explicitly stating the ordinal position, we do this by specifying the position after defining the column name and data type in the WITH statement. E.G. UserID INT 1. Please note that columns can be given any name.
SELECT
UserID,
EventType,
EventDateTime,
ProductID,
[URL]
Device,
SessionViewSeconds,
EventProcessedUtcTime,
PartitionId,
EventEnqueuedUtcTime
FROM
OPENROWSET(
BULK 'https://datalake.dfs.core.windows.net/datalakehouse/webtelemetry/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '1.0',
FIELDTERMINATOR = '|' ,
FIRSTROW = 2
)
WITH
(
UserID INT 1,
EventType VARCHAR(50) 2,
EventDateTime DATETIME2 3,
ProductID INT 4,
URL VARCHAR(50) 5,
Device VARCHAR(20) 6,
SessionViewSeconds INT 7,
EventProcessedUtcTime DATETIME2 8,
PartitionId TINYINT 9,
EventEnqueuedUtcTime DATETIME2 10
)
AS rIf we run this statement we’ll get back the following results:

We’ll now introduce a new file into the webtelemetry folder. We’ll now go through 4 scenarios that we’ll test with this new file.
1. Existing column moved to a different location in the new file
UserID moved to position 3. EventDateTime moved to position 4
As column locations are specified using ordinal positions, the query will fail if the data types are mismatched between the CSV files. In this scenario, UserID is a numeric data type and cannot be parsed as a datetime (and vice-versa with EventDateTime).
If the columns have compatible data types then the query will succeed and produce un-desirable results as it will display the column values across the files. E.G. if UserID and ProductID swapped positions in the new file, the query would succeed but there would be mis-matched data. The query would show the correct UserID values from the first file but would then show the ProductID values from the new file.
2. Column removed from new file entirely
UserID deleted from new file.
This would produce similar results to the previous scenario, columns would be out of order in the new file and would either cause a query to fail if the data types were not matched across the files or results would return but data would be in different positions. In this scenario the query would fail as the 5th position column URL (varchar) in the original file would now be in the 4th position in the new file, and the 4th position has been associated with a numeric data type.
3. New column added between existing columns in new file
DeviceOS column added to new file in 3rd position.
This would produce similar results to the previous 2 scenarios, columns would be out of order in the new file and would either cause a query to fail if the data types were not matched across the files or results would return but data would be in different positions.
4. New column added at the end of new file
DeviceOS column added to new file in 11th position.
As we are not changing column positions in the new file for existing columns, the new column will appear fine if specified in the WITH statement with the ordinal position of 11. (NULL) will appear in the results for previous files without this column.

PARSER_VERSION = 2.0
We’ll now look at Parser Version 2, we are able to use the column names within the CSV files if there is a header row in the source files (as per our example). We’ll use the HEADER_ROW = TRUE option in the OPENROWSET command. If we use Parser Version 2 with files with no header then the results will be the same as Parser Version 1 as we would need to define the columns using the ordinal positions.
Let’s reset our test by removing the new file from the webtelemetry folder and starting from the initial file. In the following query we can simply specific a wildcard (*) and no WITH statement to return results successfully.
SELECT
*
FROM
OPENROWSET(
BULK 'https://datalake.dfs.core.windows.net/webtelemetry/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
FIELDTERMINATOR = '|' ,
HEADER_ROW = TRUE
) AS rAs we are now using Parser Version 2, Serverless SQL Pools can infer the schema and return the results of the query. Please note that if the source files did not have a header and the data started on row 1, the query above would still work and return results. However, the columns would be given system generated names such as C1, C2, C3 unless a WITH statement was specified.
We can use the system stored procedure sp_describe_first_result_set to return a list of columns and their data types that Serverless SQL Pools has inferred.
EXEC sp_describe_first_result_set N'SELECT
*
FROM
OPENROWSET(
BULK ''https://datalake.dfs.core.windows.net/webtelemetry/*.csv'',
FORMAT = ''CSV'',
PARSER_VERSION = ''2.0'',
FIELDTERMINATOR = ''|'' ,
HEADER_ROW = TRUE
) AS r'We’ll get back a table listing the columns found in the source files and the data types that Serverless SQL Pools has assigned to these columns.
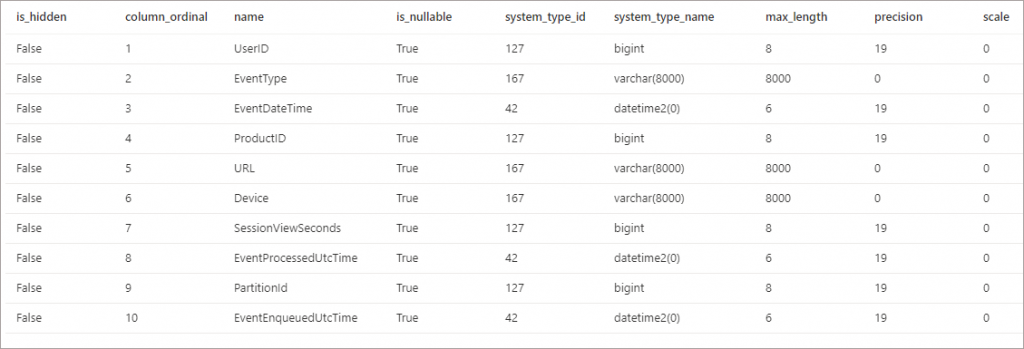
We can also just query the columns we are interested in. In the following SELECT we’ll just select 5 of the columns in the SELECT list. Parser Version 2 will allow us to just select the columns by name without specifying a WITH statement.
SELECT
UserID,
ProductID,
EventType,
Device,
EventDateTime
FROM
OPENROWSET(
BULK 'https://dhstordatalakeuk.dfs.core.windows.net/datalakehouse/schemaversion/csv/webtelemetry/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
FIELDTERMINATOR = '|' ,
HEADER_ROW = TRUE
) AS rNow let’s look at what happens when a new file is introduced and the schema of this file is different from all previous files.
1. Existing column moved to a different location in the new file
UserID moved to position 3. EventDateTime moved to position 4
If the files have a header row, then specifying the columns by name in the SELECT <column> list, using a wildcard (*), or specifying the columns in the WITH statement will successfully return the results from all files regardless of existing column ordering. Serverless SQL Pools is able to determine the location of the columns based on their names and return the results correctly.
However, if the files do not have a header row then any query will return inconsistent results due to the fact that ordinal positions need to be used to select column data. If columns are out of order across different files then those ordinal positions will not match between files. The query will fail if data types do not match. If data types do match then the column will be populated with data out of order which is extremely undesirable.
2. Column removed from new file entirely
UserID deleted from new file.
If we specify columns in the SELECT statement or using WITH we’ll see the same behaviour as the previous scenario, as Serverless SQL Pools is selecting the columns based on name it will return the columns it finds and will return NULL for columns it does not find.
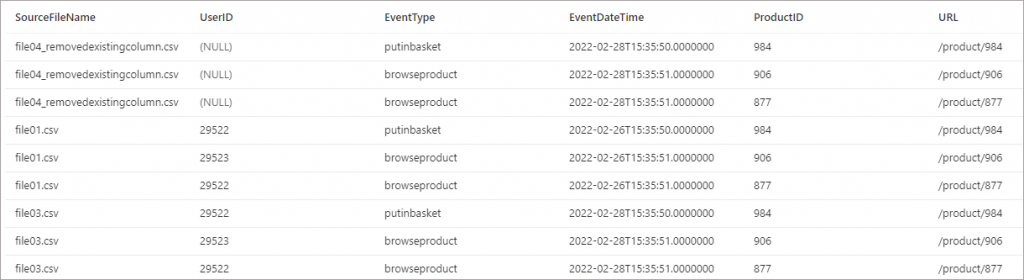
What’s interesting is if a wildcard (*) is used in the SELECT instead of explicitly stating the column names, Serverless will generate its understanding of the file schema from the first file it processes. It will then use this information to search all subsequent files. If for any reason the new file was processed first, Serverless would have no knowledge of the missing UserID column and would therefore not return that column for the rest of the files.
It’s the same situation if the files have no header row, as ordinal positions change, the query will return inconsistent results or fail entirely.
3. New column added between existing columns in new file
DeviceOS column added to new file in 3rd position.
If a new column is added in the new file in between existing columns, then for this new column to be visible in query results, the column needs to be specified in the WITH statement (not just the SELECT <column> list). Again, Serverless is able to find the columns based on their names but in this case a wildcard (*) SELECT will not work.
If we use a wildcard (*) then the new column will not be returned:
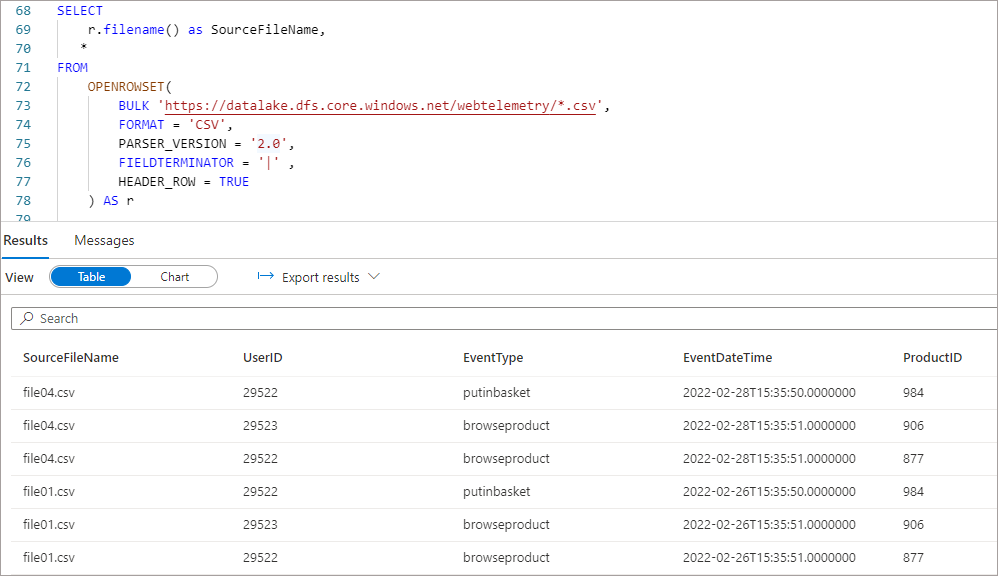
If we specify the new column name in the WITH statement, then it is returned in the results. As you can see the new column has been added to the WITH statement as the end of the column list, the ordering is not important as Serverless will find the column based on the name.
SELECT
r.filename() AS SourceFileName,
UserID,
ProductID,
EventType,
Device,
EventDateTime,
DeviceOS
FROM
OPENROWSET(
BULK 'https://datalake.dfs.core.windows.net/webtelemetry/*.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
FIELDTERMINATOR = '|' ,
HEADER_ROW = TRUE
)
WITH
(
UserID INT ,
EventType VARCHAR(50) ,
EventDateTime DATETIME2 ,
ProductID INT ,
URL VARCHAR(50) ,
Device VARCHAR(20) ,
SessionViewSeconds INT ,
EventProcessedUtcTime DATETIME2 ,
PartitionId TINYINT ,
EventEnqueuedUtcTime DATETIME2 ,
DeviceOS VARCHAR(10)
)
AS rWe get the new column displayed as per the SELECT query.
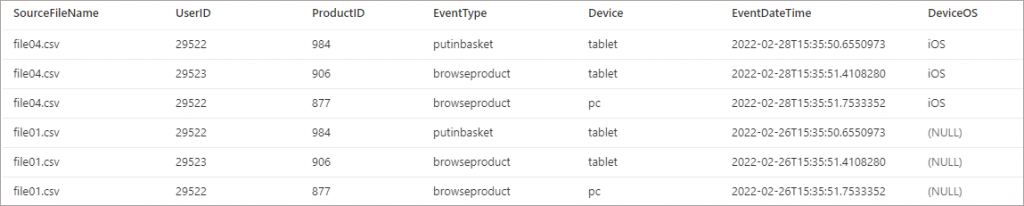
4. New column added at the end of new file
DeviceOS column added to new file in 11th position.
The results here will be the same as the previous scenario, the new column will not appear unless stated in the WITH statement of the SELECT. If a wildcard (*) is used instead of column names then the new column will not appear in results.
Conclusion
As you can see, if existing columns change position, are removed, or new columns added, it will not necessarily fail any select queries depending on the Parser Version and whether columns are explicitly stated in the select queries. Incorrect results can be generated especially if no row header is available.
I believe the main takeaway here is that for CSV files we do not want the source schema to change in Data Lake folders of existing files as we can get unpredictable results. Perhaps separate folders and Views or External Tables should be build for differing schema versions of files.
In future blog posts we’ll look at the Parquet and Delta formats.
 Andy
Andy
[…] in source data lake files which is then queried by Serverless SQL Pools in Synapse Analytics. In part 1 we looked at CSV files and several scenarios in which the structure of those CSV files changed and […]
[…] Serverless SQL Pools automatically handles changing schemas in Delta, unlike the behaviour in CSV (part 1) and Parquet (part 2) in which we did encounter undesirable […]