Microsoft Fabric Warehouse for the Database Administrator (DBA) Part 3: Fabric Compute
Overview
Welcome to part 3 of this Fabric Warehouse for the DBA series in which we’ll look at the Fabric Compute that underpins the Fabric Warehouse (and Lakehouse SQL Endpoint) service itself. We’ll look at the concept of Capacities and how they deliver the compute and also unlock the Fabric features including the Warehouse service. If you haven’t checked out the previous blogs in this series please do, starting with the overview here. In this part of the series we’ll be covering the following areas:
- Licensing: Capex vs Opex
- Fabric Compute
- Capacities
- Capacity Scenarios and Region-Binding
- Capacity Bursting and Smoothing
- Warehouse SKU Guardrails
Licensing: CAPEX vs OPEX
Before we dive into the technical part of this blog, let’s take a step back and take a look at the financial model when purchasing Fabric Capacities. This section isn’t just for DBAs (useful for CIOs, CTO, CFOs etc) but if you’re a DBA and are involved in licensing and calculating how much a company needs to pay for database infrastructure, it will be useful.
When purchasing SQL Server licenses, this purchase can be allocated to CAPEX and amortised over a period of time. E.G. buy 32 Cores-worth of SQL Server Enterprise licenses at around $240K and amortise it over 3 or 4 years. However, purchasing Fabric capacity is a subscription based purchase even with a 1 year up-front reserved pricing purchase, and it’s likely it cannot be allocated to CAPEX, it must be allocated to OPEX. If an organisation uses EDITDA then a higher OPEX cost will lead to a lower EDITDA. Of course it’ll all depend on the organisation itself, moving costs from CAPEX to OPEX may be preferable to some, to others it may be detrimental.
I’ve covered purchasing Fabric Capacities in this blog post including Pay-As-You-Go and Reserved Pricing.
It’s also worth noting here that buying a Fabric Capacity is also buying a license to use the Fabric Services themselves. Currently there are certain features in fabric that can only be unlocked at certain F SKU levels. E.G. using Private Endpoint connections to secure Azure Storage accounts can only be used with a minimum of an F64 SKU. We could look at this similar to buying SQL Server Standard vs Enterprise editions. However, if we are using a Fabric SKU we do have the options of scaling it up and down to lock/unlock these features.
The image below shows the Pay As You Go pricing for each tier of the available F SKU capacities.
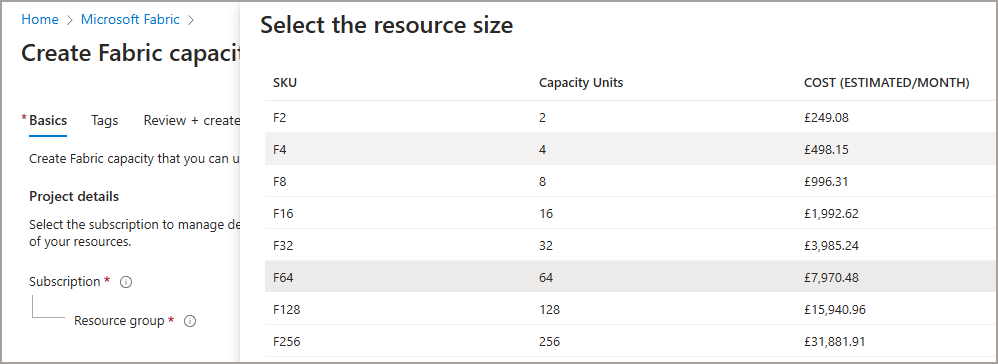
Fabric Compute
Let’s start off with the heart of Fabric, the compute itself. If we compare with SQL Server then this is simply the software (or engines) and must be installed on computers/servers to allow SQL Server to run. It’s much the same here although the Fabric compute itself is hidden behind the concept of Capacities (or F SKUs), with the unit of power measured as Capacity Units (CUs). With installing SQL Server you have a wide choice of hardware configurations, CPUs/Cores, RAM, networking, attached storage etc. With Fabric Capacities, you simply have a “size” of capacity you require to run your workloads, E.G. F2, F4, F16 etc. Within a single Power BI/Fabric tenancy, you can create multiple Fabric Capacities. These Fabric capacities are created within an Azure subscription.
If we compare with Azure Synapse Analytics we not only had multiple engines manage, from Dedicated SQL Pool, to Spark Pools, Data Explorer etc, but we also needed to manage the compute and size for these services. Now in Fabric we still have all these engines but now they are sharing the same pool of compute. Want to know how much compute a Spark pool is using? Look at the Capacity Units. How about the Warehouse service? Yes, Capacity Units.
Basic Topology
In the image below, we can see the Power BI/Fabric Workspaces allocated to Fabric Capacities of different sizes in different region. These capacities are created and managed within an Azure subscription. In order for the Fabric Warehouse service to run, the Workspace the Warehouse resides in must be attached to a Fabric Capacity.
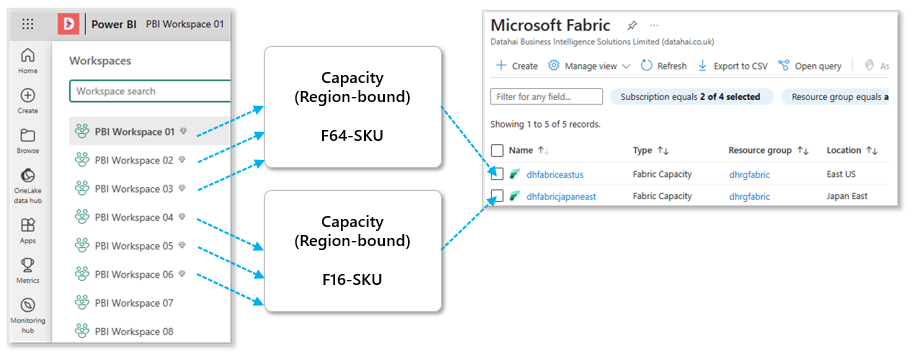
Capacity Planning
So how do we know how much “power” each F SKU can deliver? We can estimate our workloads when using SQL Server by looking at current CPU trends and RAM usage over time, if we’re looking at purchasing new hardware for a SQL Server installation then we can use these as benchmarks to plan. Fabric is no different really, we will need to look at running workloads within specific Fabric F SKUs and track trends over time and usage consumption (we tackle monitoring usage in a later blog) to understand how each workload is affecting usage consumption.
Scale Up vs Scale Out
The terms Scale-Up and Scale-Out have been used for decades now to define scenarios in which you can “increase compute resources” in a data platform for faster processing, less bottlenecks, & increase concurrency. Scale-Up deals with increasing the size of available resources for an instance of compute/server, E.G. adding a faster CPU, increasing the amount of RAM. Scale-Out deals with how many instances of compute/servers are in use for dealing with workloads. Fabric operates in much the same way for both of these terms, we can Scale a Fabric capacity up by increasing the F SKU, and we can Scale Fabric workloads out by using multiple Fabric capacities. Although Scaling Out using multiple Fabric capacities isn’t true scaling out as workloads will still need to be run on specific capacities but we could run certain workloads on one capacity, and other workloads on another capacity.
F SKUs
Fabric capacities are both the compute itself and also how to unlock the Fabric functionalities themselves. The term F SKU is the item you are actually purchasing (in the world of Power BI we have multiple SKUs, P, A, EM) and this will include the size of the SKU which is the amount of compute you are entitled to use. This entitlement is called Capacity Units (CU) and range from the smallest which is F2 and the largest F2048.
If you already have a Power BI tenant, when you purchase an F SKU you then need to assign Power BI/Fabric Workspaces to this capacity to unlock the Fabric functionality. You can then create Fabric items such as Lakehouses, Warehouses, Pipelines, Spark Notebooks and away you go.
Capacities play multiple roles, they are the compute itself but also what unlock the ability to create Fabric items. When creating a Fabric Capacity, regardless whether it’s via Azure or through Premium licensing, that capacity will be allocated to a specific region. The way to actually unlock the usage of Fabric Capacities is to allocate Power BI/Fabric Workspaces to these capacities. In the image below we can see 4 Power BI/Fabric Workspaces, 2 workspaces are allocated to a specific capacity, the other 2 workspaces allocated to the other capacity. Each of those capacities could exist in a different region.
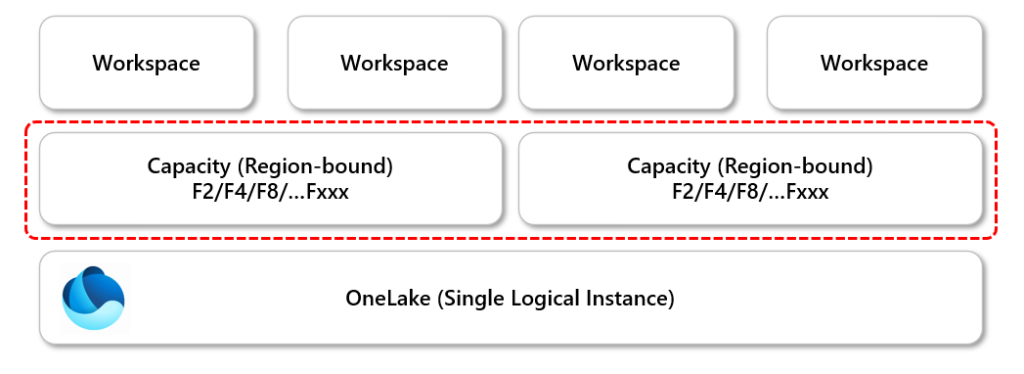
In the image below I have created 3 Fabric Capacities in 3 different regions. I can allocate a Fabric Workspace to any of those capacities and the data within that workspace will be region-bound to that capacity’s region. If you load data between Fabric Workspaces, then data can be moved across geographical boundaries and also incur egress charges.

Allocate Workspaces to Capacities
We can allocate Workspaces to Fabric Capacities in the Power BI/Fabric portal by using the Workspace settings themselves. By clicking Edit on the License Info tab, the Workspace can be allocated/deallocated to a specific Fabric Capacity. In the image below, this Workspace is allocated to a Fabric Trial capacity.
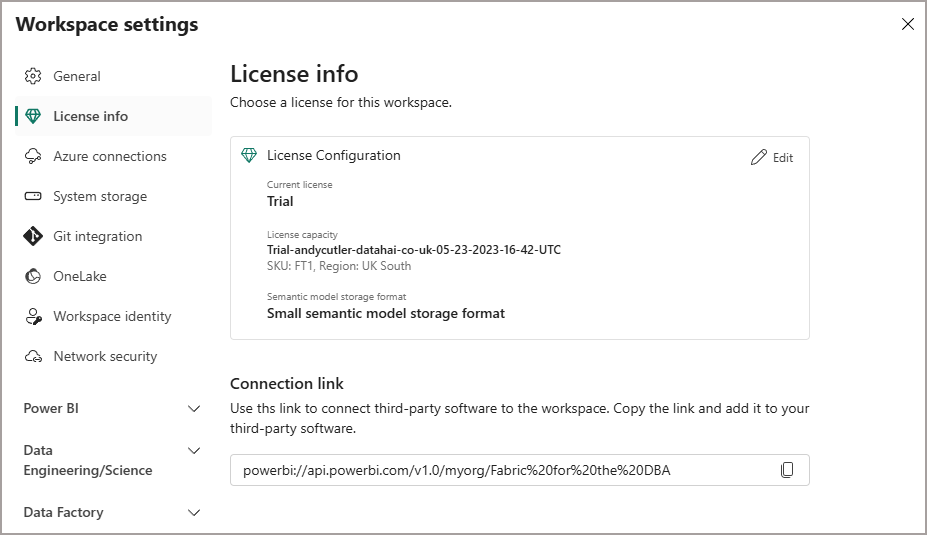
Scenarios
Let’s look at a handful of scenarios covering allocating Fabric Workspaces to capacities.
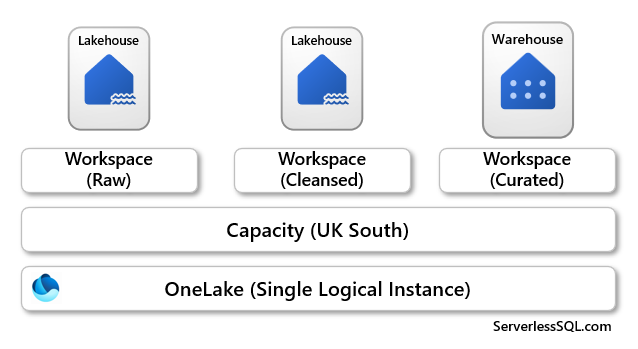
Create Items in Workspaces Assigned to Fabric Capacity in same Region
In this scenario, 3 Workspaces are allocated to a single Fabric Capacity that is based in the UK South region. All the data created within the Lakehouses and Warehouse within those Workspaces will all reside in the UK South region.
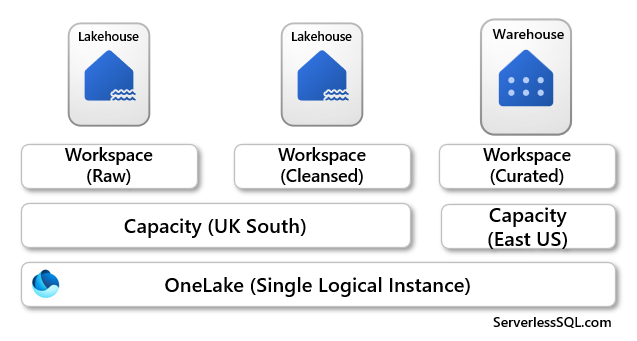
Create Lakehouses in Workspaces Assigned to Fabric Capacities in Different Regions
If we now look at a scenario in which we have the same 3 Workspaces with Lakehouses and a Warehouse in each workspace, except now we have an additional Fabric Capacity that has been created in the East US region. If we allocate the Workspace that contains the Warehouse to this new capacity, even though it’s in the same Fabric tenant, we will be moving data across regions if we load the Warehouse from the Cleansed Lakehouse. Not ideal as this may break any data protection, plus there could be egress fees across regions (pricing page here doesn’t show any cost information yet for networking Microsoft Fabric – Pricing | Microsoft Azure).
If the data is in compliance when moving regions, it may prove useful to have data situated close to where it’s being used.
Pausing & Resuming Capacities
You have the option to pause Fabric capacities when not in use, this makes sense if you’re using Pay As You Go pricing as you can run a capacity for a certain amount of time and then switch it off. This could be useful for development/testing purposes. Although “saving costs” has a tipping point though when its possible that buying Capacities using Reserved Pricing may be most cost effective that pausing PAYG capacities. Please read this blog in which I go into PAYG vs Reserved Pricing.
Capacity Bursting & Smoothing
Although we can choose the F SKU Capacity size when purchasing a capacity, and also change its size during operation (e.g. scaling from an F2 to an F64), we may encounter data workloads that require “a little more” compute than what is currently allocated. In the world of SQL Server there’s not much we can do if the server itself reaches a ceiling in terms of CPU/RAM, workloads can/will fail even with the best efforts of the server itself. With Fabric, Microsoft will let you “burst” beyond your current F SKU size to allow spiked workloads to complete. I like to view Bursting as a technical process, because you are being given more compute to allow a workload to compute. However, there’s no such thing as a free lunch, and you have to pay back this burst capacity. You will likely do this when your capacity is not doing much, and this is called Smoothing. I like to view Smoothing as a billing process, whereby Microsoft will average out the bursted workloads into a specific period of time, e.g. 24 hours in terms of data processing. If your capacity is bursting a lot and is not able to smooth out over a period of time you will encounter throttling. If you abuse bursting, e.g. running workloads that burst constantly and then pausing a capacity so that smoothing cannot occur, Microsoft can charge you for the additional bursted compute.
Warehouse SKU Guardrails
Although Microsoft will let you burst beyond your existing F SKU capacity size, this won’t be unrestricted and has a limit. There are guardrails in place to make sure things don’t get out of hand and potentially causing throttling. Below is a table from Microsoft’s documentation that outlines the guardrail limit at each capacity size. As you can see, the higher the F SKU, the less the scale factor becomes.
| Fabric SKU | Equivalent Premium SKU | Baseline Capacity Units (CU) | Burstable Scale Factor |
|---|---|---|---|
| F2 | 2 | 1x – 32x | |
| F4 | 4 | 1x – 16x | |
| F8 | 8 | 1x – 12x | |
| F16 | 16 | 1x – 12x | |
| F32 | 32 | 1x – 12x | |
| F64 | P1 | 64 | 1x – 12x |
| F128 | P2 | 128 | 1x – 12x |
| F256 | P3 | 256 | 1x – 12x |
| F512 | P4 | 512 | 1x – 12x |
| F1024 | P5 | 1024 | 1x – 12x |
| F2048 | 2048 | 1x – 12x |
Conclusion
In part 4 we have looked at Fabric Capacities themselves and how they deliver the compute and Fabric features themselves. In Part 3 we’ll be looking at the Warehouse (and Lakehouse SQL Endpoint) SQL Engine itself.
References
- Microsoft Fabric concepts – Microsoft Fabric | Microsoft Learn
- Scale your Fabric capacity – Microsoft Fabric | Microsoft Learn
- Fabric operations – Microsoft Fabric | Microsoft Learn
- Burstable capacity – Microsoft Fabric | Microsoft Learn
- Workload management – Microsoft Fabric | Microsoft Learn
- Evaluate and optimize your Microsoft Fabric capacity – Microsoft Fabric | Microsoft Learn



