How does Serverless SQL Pools deal with different file schemas? Part 3 – Delta
Welcome to the 3rd and final part in this blog series in which we’re looking at how Azure Synapse Analytics Serverless SQL Pools deals with changing schemas in CSV (delimited), Parquet, and Delta formats.
The way Serverless SQL Pools handles this is different across different formats and scenarios, which include:
- The order of columns change
- Existing columns are removed
- New columns are added
The way that both CSV and Parquet handle schema changes is different to Delta. Delta has an option to evolve the schema as new source attributes arrive, we can use this option to either deny or accept these schema changes into the destination Delta files. We can enable this feature and let Delta do the hard-work in terms on managing changing schemas, if we so wish. Serverless SQL Pools is then able to query this data natively.
In this blog post we’ll take a quick look at the Delta format before loading data into the Delta format and then making modifications to the original schema. Then testing how Serverless SQL Pools handles this when we query this Delta data.


Delta Format
Delta is an opensource format based on the Parquet file format and forms the storage and transactional consistency backbone of a lakehouse architecture. Delta not only stores the data, the schema information such as column data types and statistics, but also contains a transaction log which is located in the storage system alongside the files. This allows for transactional consistency when reading and writing data, and also allows point-in-time analysis as data is stamped with datetime values as and when changes are made. One of the features of Delta we’ll be using in the blog post is Schema Evolution, we can enable a loading process to amend the schema of a Delta “table” (a folder in the data lake) to add new columns for example.
One of the features of Delta we’ll be using in the blog post is Schema Evolution
Serverless SQL Pools is often used as the “serving” layer part of a lakehouse architecture as it supports reading the Delta format. Not all features are supported such as time-travel, so when data changes in the Delta table Serverless will query the latest values only.
You can read more here and watch here.
Mapping Data Flows
To load the data from the source to the Delta sink (a Sink being the destination in Synapse Pipelines terminology) I am using a simple 4 task Mapping Data Flow which takes data from a source, chooses the columns to process, adds a datetime stamp to the data, and then finally loads to a Delta table (a folder in the Data Lake). This pipeline will be amended as we work through the scenarios below, the SelectColumns task will be modified to amend/add/remove columns to test our differing schema scenarios.
Basic Pipeline

Delta Sink Settings
The settings for the SinkToDelta task are as follows. I have selected None in Table Action as I will be repeatedly running the pipeline and I want the source data to be appended to the Delta table (not overwritten or truncated) to see the results of the schema changes. Each pipeline run will add 3 rows to the destination Delta sink.
I have activated Merge Schema in the Delta Options to allow new columns to be added. If this option was de-activated then the pipeline would fail if an attempt was made to add new columns to an existing Delta table.
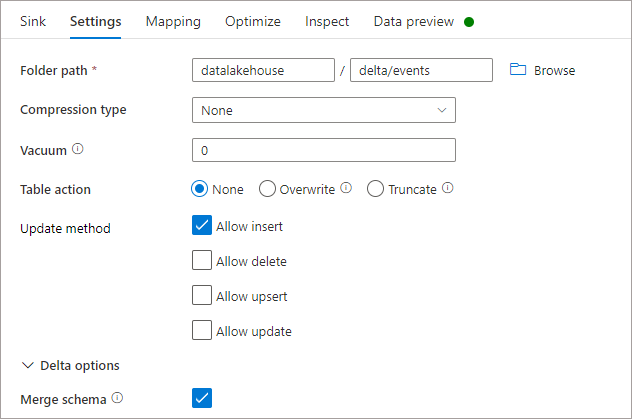
Initial Dataset
We’ll start with an initial dataset of 5 columns. We’ll be using Synapse Pipelines Mapping Data Flows to write out to Delta in a folder in an Azure Data Lake Gen2 account. The initial dataset contains:
- UserID
- EventType
- EventDateTIme
- ProductID
- LoadDate
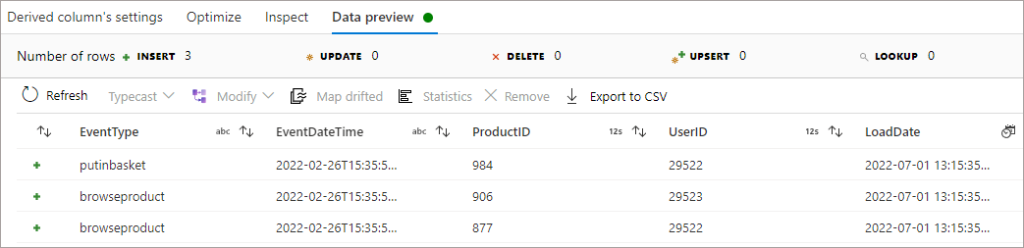
Once the pipeline has been run, we can query the Delta table using SQL and the Delta format in the OPENROWSET command in Serverless SQL Pools. We need to point to the root folder of the Delta table (folder) where the delta transaction log exists, in this blog this location is \delta\events\
SELECT
UserID,
EventType,
EventDateTime,
ProductID,
LoadDate
FROM
OPENROWSET(
BULK 'deltablog/events/',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Delta'
) AS r
ORDER BY LoadDate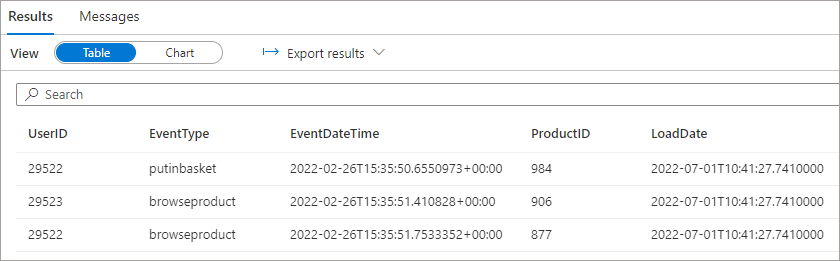
Please note that the SQL queries we’ll be using do not specify the columns and data types using the WITH statement. The test here is to test how Serverless SQL Pools handles the schema changes without us “helping” Serverless. At the end of this blog there is an example SQL statement using WITH to define columns and data types, which is recommended practice.
Delta Log
If we browse to the folder specified in the Delta sink activity we can see the Parquet file that was written out and also a folder called _delta_log. This folder contains .JSON files which contain the transactional activity on the Delta table (folder).

Scenario: Moving Existing Column To Different Location
We’ll now move the UserID column from 1st to 4th position in the dataset, run the pipeline again and observe the output. The changes made are in the SelectColumns task in the Mapping Data Flow.
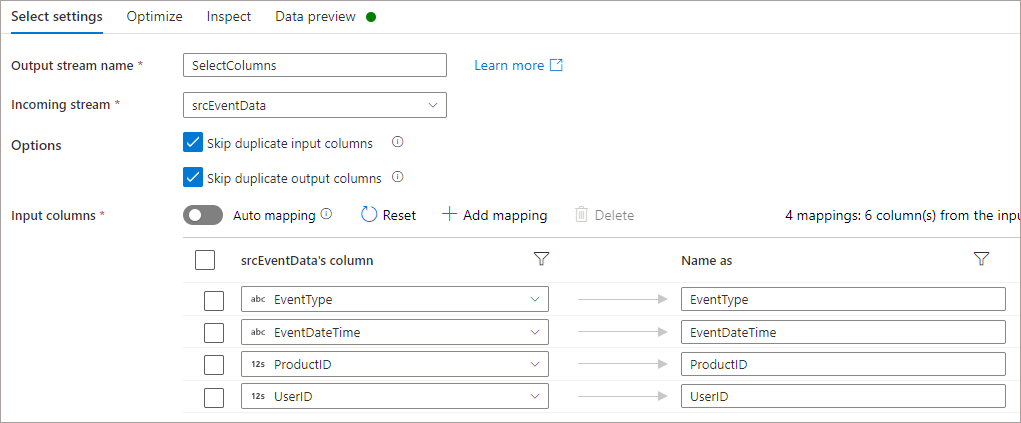
If we run the SQL statement as specified above, the results are returned correctly with the UserID column being picked up and returned successfully..
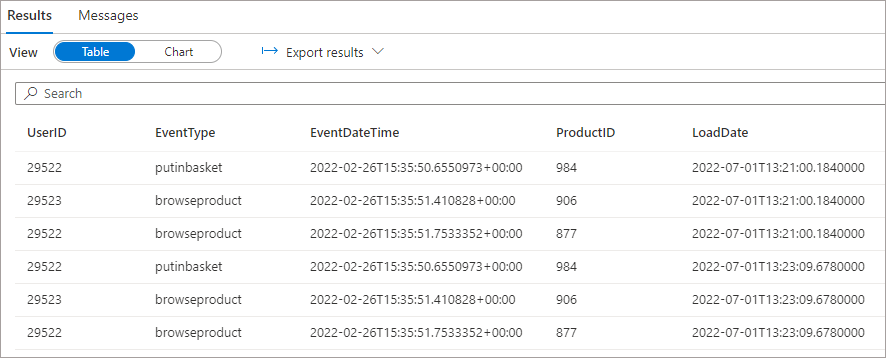
Scenario: Remove Existing Column
We’ll now remove the UserID column from the SelectColumns task and re-run the pipeline. By running the same SQL statement as above we can see the UserID column is still populated with values from the previous pipeline run, but is NULL for the most recent run where the column doesn’t exist anymore.
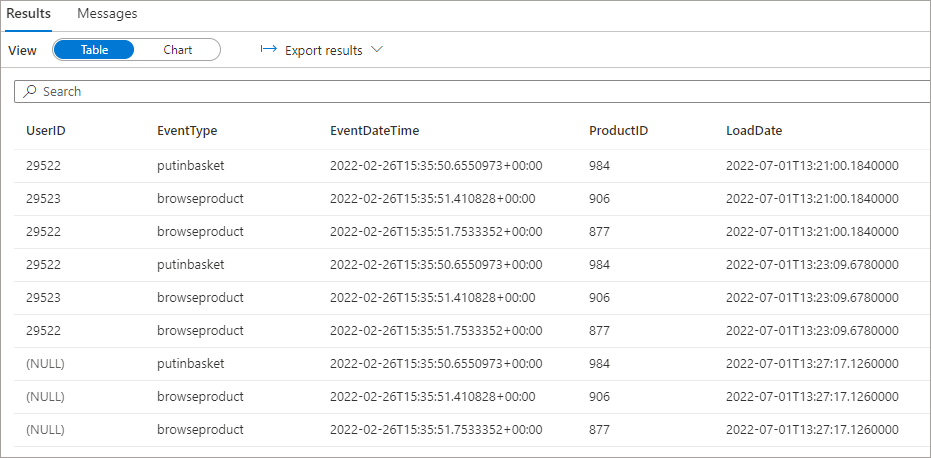
Scenario: Add New Column
The final test will be to add a new column to the SelectColumns task, Device, and run the pipeline again.
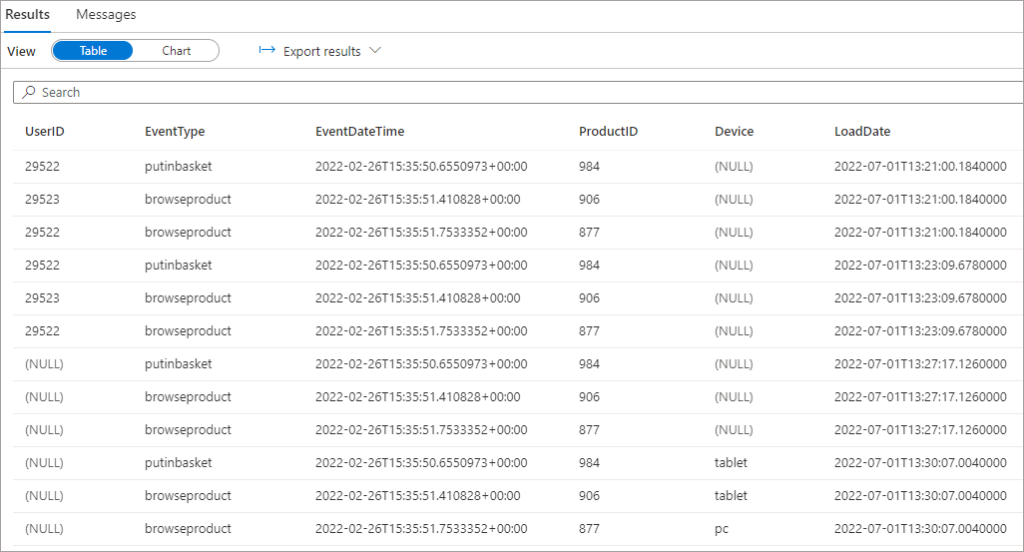
We’ll add the new column in the SELECT statement. Note that we are not using the WITH keyword in the SQL statement to add in the new column, we add it to SELECT columns list. This is due to the way Serverless SQL Pools is able to read the Delta transaction log and understand the latest schema of the Delta table (folder).
SELECT
UserID,
EventType,
EventDateTime,
ProductID,
Device,
LoadDate
FROM
OPENROWSET(
BULK 'deltablog/events/',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Delta'
) AS r
ORDER BY LoadDate
We’ve specified the column in the SELECT list previously but it’s worth noting that SELECT * also works without specifying columns in a WITH statement (refer to blog part 2), so the following code will also work when column are removed/added.
SELECT
*
FROM
OPENROWSET(
BULK 'deltablog/events/',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Delta'
) AS r
ORDER BY LoadDateWe don’t have to explicitly specify columns as the Delta format will automatically update the schema information for the table (folder) which Serverless SQL Pools is able to interpret. However, it’s best practice to specify the columns and data types using a WITH statement.
SELECT
UserID,
EventType,
EventDateTime,
ProductID,
LoadDate
FROM
OPENROWSET(
BULK 'deltablog/events/',
DATA_SOURCE = 'ExternalDataSourceDataLakeMI',
FORMAT = 'Delta'
)
WITH
(
UserID INT,
EventType VARCHAR(20),
EventDateTime DATETIME,
ProductID SMALLINT,
Device VARCHAR(10),
LoadDate DATETIME2
) AS r
ORDER BY LoadDateConclusion
In this blog post we’ve seen how Serverless SQL Pools automatically handles changing schemas in Delta, unlike the behaviour in CSV (part 1) and Parquet (part 2) in which we did encounter undesirable behaviour.







2 thoughts on “How does Serverless SQL Pools deal with different file schemas? Part 3 – Delta”
Comments are closed.