Business Continuity & Disaster Recovery in Fabric
Overview
I’ve been turning my attention to disaster recovery processes in Microsoft Fabric recently, to understand what can be done in the event of the unthinkable happening…I’ll likely dive deeper into each area in this blog over the coming weeks.
Let’s face it…things go wrong. And when they do go wrong, we need ways of making it right. In today’s “data driven” age, ensuring business continuity when things go wrong is extremely important. With Microsoft Fabric, it’s Software-as-a-Service (SaaS) so how can we ensure we can continue to work with data in the event of a disaster? This blog post explores some key points around understanding and implementing business continuity and disaster recovery (BCDR) in Microsoft Fabric.
What is Disaster Recovery?
Disaster recovery refers to the methods, practices, and technologies organizations use to restore data and IT access after a technology-related disaster. Would you believe it…there’s an ISO entry as well…according to ISO 22301:2019, it is a crucial component of business continuity management systems, ensuring security and resilience.
Types of Disasters
Broadly speaking in my opinion, disasters can be categorized into two main areas:
- External Disasters: These include data center technical failures, network issues (it’s always DNS, right?), and natural disasters.
- Internal Disasters: These involve accidental deletion of objects, data removal (truncate/delete), and code deletion by people.
Azure and Regions
Before looking at Fabric, let’s explore Microsoft Azure for a minute. Azure’s global infrastructure is divided into geographical regions, each consisting of multiple data centers. Certain regions are paired to allow for region failover, enhancing redundancy and availability.
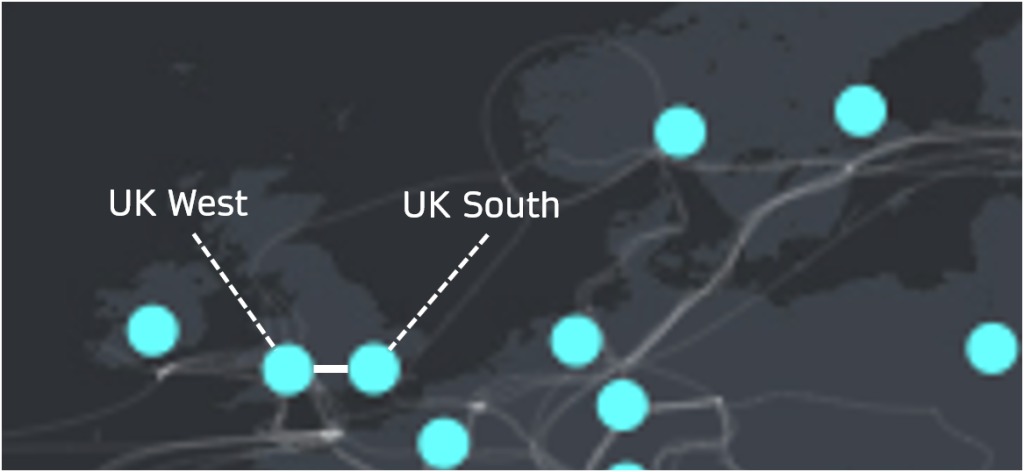
For instance, UK South is paired with UK West therefore any Azure services that support Geo-redundancy will have data replicated from UK South to UK West. UK West will activate in the event of UK South becoming unavailable.
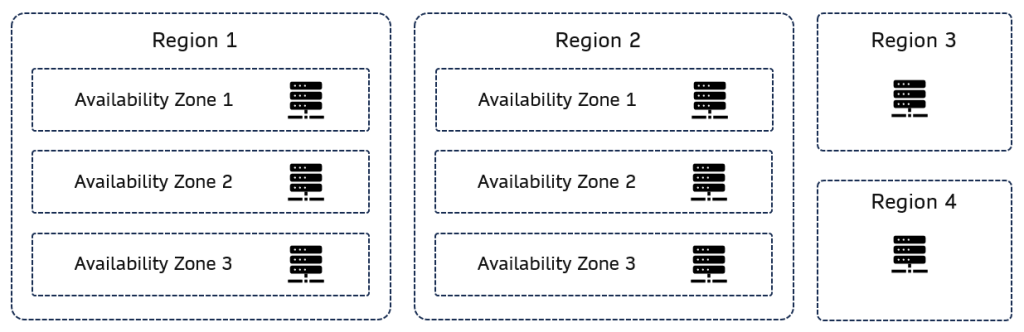
Availability Zones
Each Azure region consists of multiple availability zones. These zones are the data centres and having multiple AZs in a region provides redundancy and ensures high availability as services/data are replicated and available in the other AZs. These zones are designed to protect applications and data from data center failures. Certain regions don’t have multiple AZs so if you operate in those regions, then you’ll need to implement some form of data sync to another region.
Fabric Zone Redundancy
In Microsoft Fabric, each service in each region may have (availability) zone redundancy automatically enabled. This ensures that services remain available even if one zone fails as the other zones pick up the slack. This is an example of which Europe regions and Fabric workloads have zone redundancy.

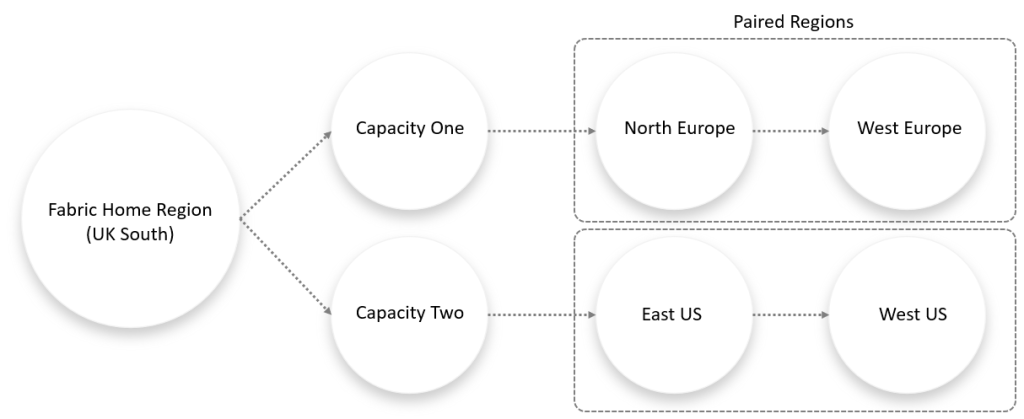
Fabric Tenant Home
Every Fabric tenant has a “home” region, determined when the tenancy is created. This home region is crucial for understanding the primary and secondary regions for BCDR. E.G my own tenant has been created in UK South, then I have created 2 Fabric Capacities that are located in North Europe and East US. Both these capacities have a paired region where data can be synced to (if BCDR settings are enabled…more on this later in this blog).
Options
Let’s look at options when considering business continuity, disaster recovery, and “preventing “pro-active” measures in preventing problems.
Security Considerations
Having a robust security posture is key to help prevent issues. Security can be applied at various levels, including tenant, capacity, workspace, workloads (warehouse, lakehouse etc) and object levels (tables). Granular permissions (GRANT/REVOKE/DENY) help restrict access appropriately. I’ve seen many a forum post asking why their users have so much control over workloads in a workspace, only to find that permissions have been applied at the whole workspace level. In my opinion, workspace level permissions are far to “over-reaching” so you need to be very careful when applying these.
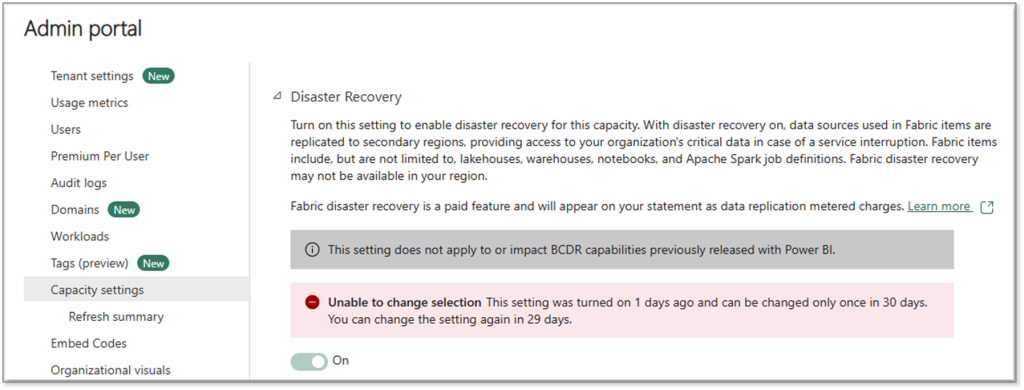
BCDR Settings in Fabric
Within the Fabric Admin portal, BCDR settings can be toggled on or off for each capacity. This being a setting for each capacity is key, perhaps not all of your workloads need data syncing to a paired region. Key considerations include:
- Cost: Both storage and compute units (CUs) are factors.
- Settings Frequency: You can only set this toggle once every 30 days
- Syncing: OneLake data is synced asynchronously, which may lead to data loss.
- Initial Latency: Can be up to 7 days to start syncing depending on data volume.
- Recovery: Not automated and requires manual intervention…more on this later in this blog.
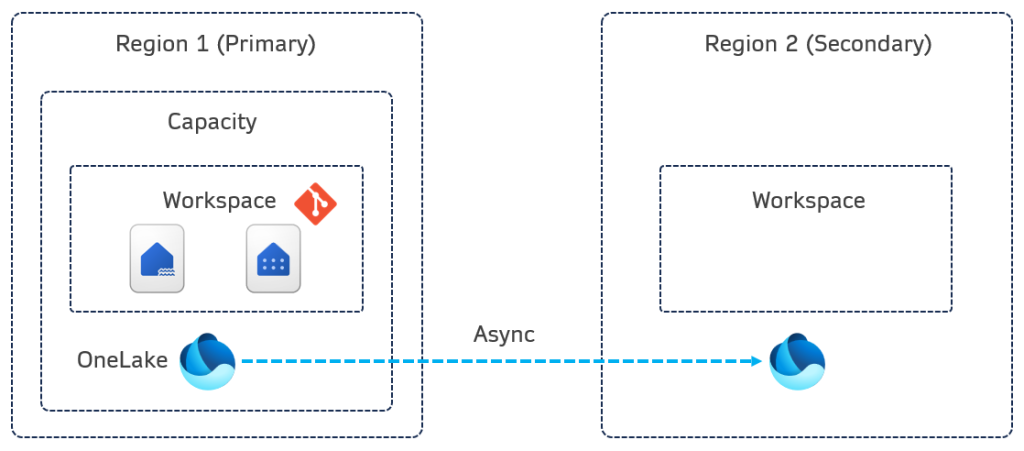
Environment Replication
BCDR replication syncs OneLake data from the primary region to the secondary region. This involves copying data and files to ensure availability in case of a disaster. This is important to note, only the OneLake data is being synced, not the workload itself. E.G for a lakehouse, the files and data are synced to the paired region, but not the actual lakehouse schema itself. This is the same for the Warehouse service too, the BCDR setting does not create a read-replica in another region (if we were using a SQL Server terminology), it simply syncs the data.
Also note that the workspace is connected to a Git repo (Azure DevOps, GitHub) to backup the code.
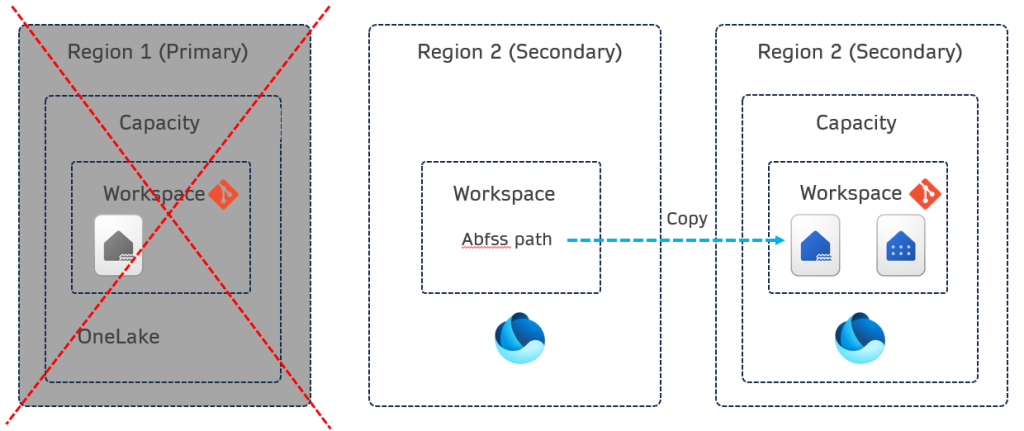
Recovery Process
In the event of the primary region becoming unavailable, failover to the secondary region occurs. Recovery involves updating the recovery workspace using Git, then copying files and data from the primary to the secondary region. This process ensures that data is restored to a known good state.
Steps
- Create a new Workspace and assign to a Capacity in the secondary region
- Update the workspace from Git to sync any items (pipelines, notebooks, lakehouse, warehouse)
- Run a data loading process to get the data/files from the secondary region and populate the new workspace.
When region failover occurs, the data is available at the same workspace/item GUID from the primary region. Here’s an example of code to restore. Note that I’ve tested recovery times, and saw around 2 hours to restore 1TB of Delta tables.
newlakehouse = "6e98a271-1f2a-4b3d-bf59-ec3f004f09e1"
#destination Lakehouse Files section
destination="abfss://fa58f709-f0f1-4f64-b28d-59373743c064@onelake.dfs.fabric.microsoft.com/" + newlakehouse + "/Files"
#get folders and files
files = mssparkutils.fs.ls('abfss://a8c5d3d4-6e21-491e-a865-9bad3186ca4d@onelake.dfs.fabric.microsoft.com/c9e37d93-a459-41b1-87f5-3c916ae25f42/Files')
#recursively restore
for file in files:
source=file.path
mssparkutils.fs.cp(source, destination, True)
###################################################################################
#destination Lakehouse Tables section
destination="abfss://fa58f709-f0f1-4f64-b28d-59373743c064@onelake.dfs.fabric.microsoft.com/" + newlakehouse + "/Tables"
#get all tables
files = mssparkutils.fs.ls('abfss://a8c5d3d4-6e21-491e-a865-9bad3186ca4d@onelake.dfs.fabric.microsoft.com/c9e37d93-a459-41b1-87f5-3c916ae25f42/Tables')
#recursively restore
for file in files:
source=file.path
mssparkutils.fs.cp(source, destination, True)
Workload Specifics
Because Fabric uses Delta Lake under the hood in Fabric, Delta Lake drives certain recovery processes. It allows for separation of storage and compute, making data transportable.
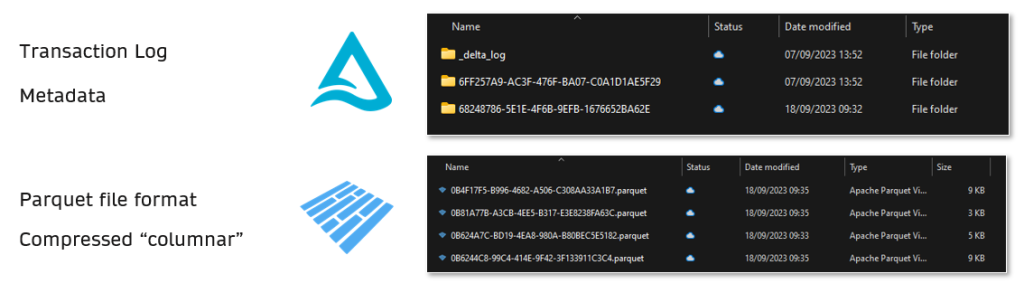
Lakehouse & Warehouse: These can be restored in place or using cloning and time travel features to revert to previous versions or known good states.
Multi-Site Active/Active
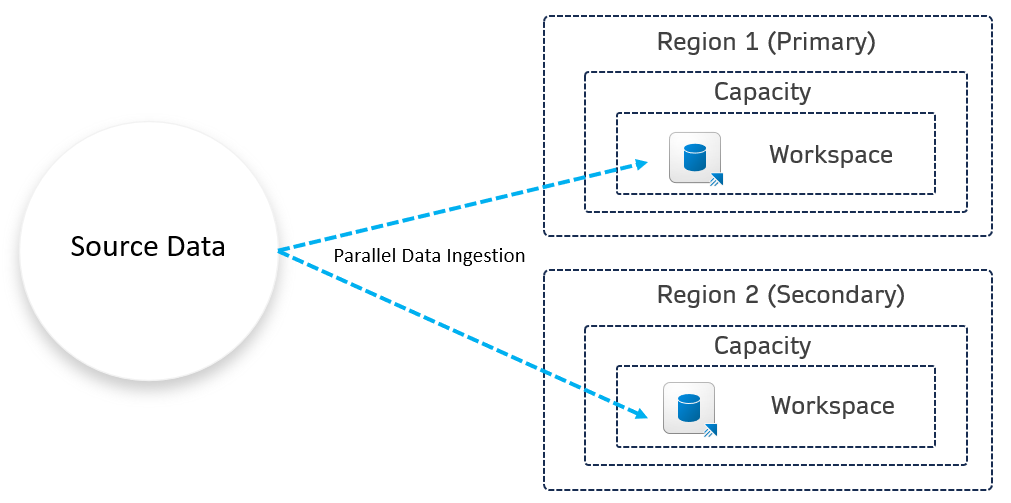
This term sounds fancy, but in-fact just means “do it yourself!” For certain workloads, such as KQL databases (Realtime Analytics), a multi-site active/active setup can be used. This involves parallel data ingestion across primary and secondary regions. This isn’t exactly perfect as will introduce more cost, be warned!
Conclusion
Ensuring business continuity in Microsoft Fabric involves a combination of disaster recovery strategies, security measures, and careful planning. There’s no one single setting to do everything, and even when enabled BCDR you have the “shared responsibility” of recovery in the event of a disaster. Just plan for when things go wrong, please.



