Testing Error Handling in Serverless SQL Pools
A recent feature to be released for Serverless SQL Pools is error handling when processing external data (please see the November 2021 Synapse Analytics update). When querying external data, Serverless SQL Pools does not know until query time if any data is malformed or will cause an error. For example, if an External Table or View is created over well-formed data, but at a point after the objects were created malformed data is added to the source then query failure is likely.
With the new error handling feature added to the OPENROWSET operation, invalid rows can be redirected to a file for inspection whilst valid rows are still processed and the overall query will continue to run until the MAXERRORS parameter is hit.
It’s well worth noting that even if your query fails, you’ll still be charged for any data processed.
Support
The official documentation states that using PARSER_VERSION 2.0 is not supported for Delimited/CSV/JSON formats, so we must use PARSER_VERSION 1.0. There is also no support for Parquet and Delta file formats. This is disappointing as Parquet and Delta are becoming more popular for data lake/lakehouse workloads. Hopefully in the not-too-distant future support will be extended.

Scenario
To test error handling, I’ve introduced malformed CSV data into a folder within the data lake. The CSV data itself is a small dataset containing ~1 million rows across 60 folders in Azure Data Lake Gen2.
Correctly Formatted Data
The correctly formatted CSV data has 11 columns separated by a pipe delimiter.

Incorrectly Formatted Data
The incorrectly formatted data contains a corruption of row and column data with data type incompatability.

Running Queries Without Error Handling
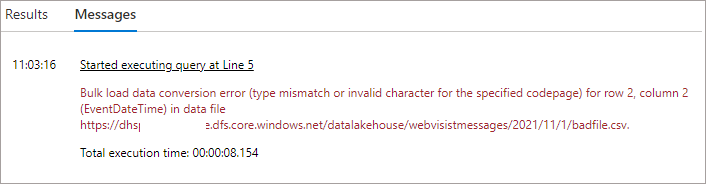
What happens when we run a query without error handling and Serverless SQL Pools encounters an issue with the source data? We get a failed query and any appropriate error message. If we run an aggregate SQL query over the CSV data that contains the malformed data, we get no results returned and an error:
SELECT
EventType,
EventDateTime,
COUNT(*) AS EventCount
FROM
OPENROWSET
(
BULK 'webvisistmessages/*/*/*/*.csv',
DATA_SOURCE = 'ExternalDataSourceDataLake',
FORMAT = 'CSV',
PARSER_VERSION = '1.0',
FIRSTROW = 2,
FIELDTERMINATOR ='|'
)
WITH
(
EventType VARCHAR(50) 2,
EventDateTime DATE 3
)
rwt
GROUP BY
EventType,
EventDateTime
Running Queries With Error Handling
We’ll now add the error handling syntax to the SELECT query. We’ll specify a maximum error count of 10, this allows up to 10 rows to error before the overall query will fail. We also specify a data lake location to save any errors to.
Syntax Added to OPENROWSET
MAXERRORS = 10
ERRORFILE_LOCATION = ‘errorhandlingtest/csv/errors’
ERRORFILE_DATA_SOURCE = ‘ExternalDataSourceDataLake’
SELECT
EventType,
EventDateTime,
COUNT(*) AS EventCount
FROM
OPENROWSET
(
BULK 'webvisistmessages/*/*/*/*.csv',
DATA_SOURCE = 'ExternalDataSourceDataLake',
FORMAT = 'CSV',
PARSER_VERSION = '1.0',
FIRSTROW = 2,
FIELDTERMINATOR ='|',
MAXERRORS = 10,
ERRORFILE_LOCATION = 'errorhandlingtest/csv/errors',
ERRORFILE_DATA_SOURCE = 'ExternalDataSourceDataLake'
)
WITH
(
EventType VARCHAR(50) 2,
EventDateTime DATE 3
)
rwt
GROUP BY
EventType,
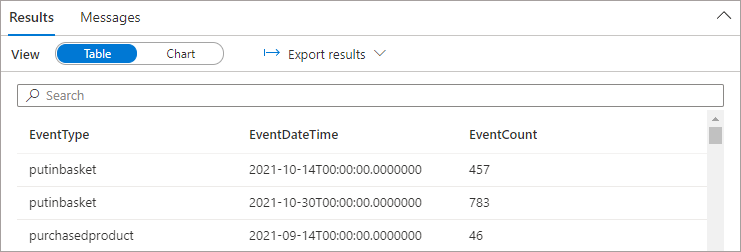
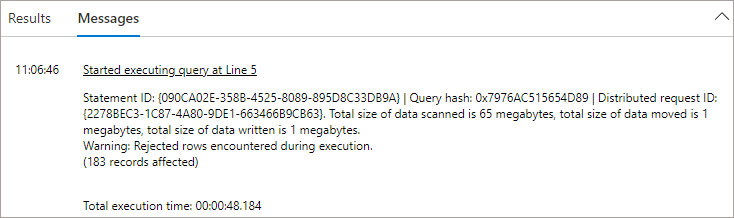
EventDateTimeThis time we see results in the Results window and in the Messages window we see that rejected rows were encountered.
If we browse to the errorhandlingtest/csv/errors folder we can see the following:

Under the _rejectedrows folder will be datetime stamped folders with an error.json file and a row.csv file (containing the actual data).
Error.json
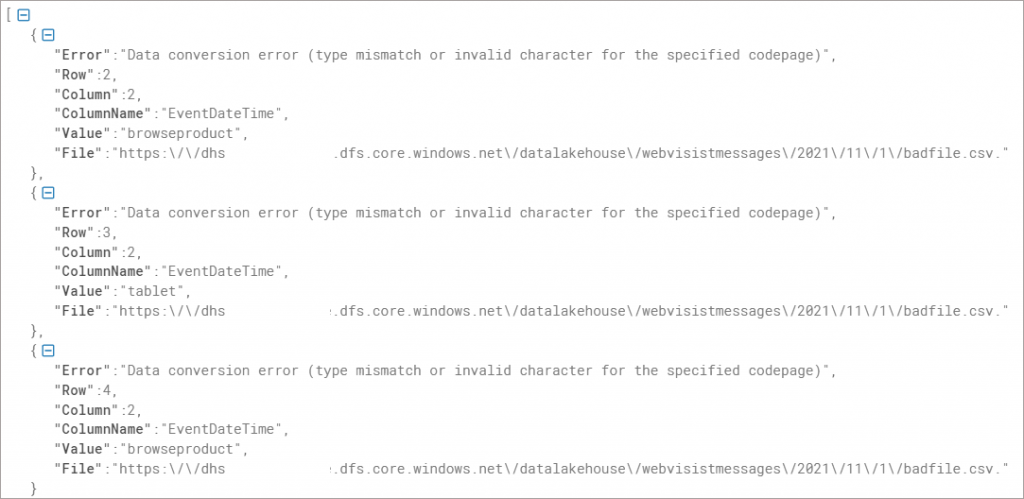
The Error.json file contains specific information about each row that could not be processed.
Create View to Select from Errors Folder
If we use the same root location to store any error files we can create a master view to see any errors logged.
CREATE VIEW dbo.ShowFileErrors
AS
SELECT
[Error],
[Row],
[Column],
ColumnName,
Value,
[File],
rowdata.filepath(1) AS ErrorFolderName
FROM OPENROWSET(
BULK 'errorhandlingtest/csv/errors/_rejectedrows/*/error.json',
DATA_SOURCE = 'ExternalDataSourceDataLake',
FORMAT = 'CSV',
FIELDTERMINATOR ='0x0b',
FIELDQUOTE = '0x0b',
ROWTERMINATOR = '0x0b'
) WITH (doc NVARCHAR(MAX)) AS rowdata
CROSS APPLY openjson (doc)
WITH ( [Error] VARCHAR(1000) '$.Error',
[Row] INT '$.Row',
[Column] INT '$.Column',
ColumnName VARCHAR(1000) '$.ColumnName',
Value VARCHAR(1000) '$.Value',
[File] VARCHAR(1000) '$.File')This view forms part of the serverlesssqlpooltools resources over on GitHub.
Performance Overhead
Let’s now turn our attention to any performance overhead. For this test we used the same two SQL queries as seen earlier in this blog, one query has error handling enabled, and the other query does not have it enabled. As we know the query without error handling will fail if bad data is detected, we will remove the bad data so both queries will succeed.
No Error Handling Enabled
When we run the SQL query without error handling enabled then we see the following time in seconds over 5 runs:
| Run | Time in Seconds |
| 1 | 15 |
| 2 | 9 |
| 3 | 8 |
| 4 | 14 |
| 5 | 9 |
Without error handling enabled we see results returned anywhere from 8 to 15 seconds.
Error Handling Enabled
When we run the SQL query with error handling enabled we see the following time in seconds over 5 runs:
| Run | Time in Seconds |
| 1 | 44 |
| 2 | 44 |
| 3 | 55 |
| 4 | 42 |
| 5 | 45 |
With error handling enabled we see an increase in overall query time.
Conclusion
In this blog we’ve looked at the recent new error handling feature for Serverless SQL Pools. It is currently limited to delimited/JSON data with PARSER_VERSION=1.0. No support for PARSER_VERSION=2.0 or Parquet/Delta will limit its use-case as Parquet/Delta is becoming a popular file choice for data lake/lakehouse analytics.






