Exploring Open Mirroring in Microsoft Fabric
Overview
Announced at Microsoft Ignite on November 24 were a batch of new features for Fabric, the most exciting and useful to me was Open Mirroring. This feature allows data to be mirrored from any data source into Fabric, which then manages inserts, updates, and deletes, presenting the data in a query-able format via the SQL Endpoint. This represents a significant advancement from previous mirroring capabilities, which were limited to sources such as SQL databases, managed instances, and Cosmos DB.
Well, I say any data…in fact the data needs to be in the parquet file format and has specific requirements around naming conventions, we’ll go into that in this walkthrough.
Process
A Landing Zone is created when a Mirroring Database is created. This Landing Zone is a folder within OneLake and can be accessed using a specific URL. To create a Delta “table” in the mirrored database, you must create a folder in the Landing Zone. Each folder then must have a _metadata.json file (explained in this blog). Each folder then operates independently in terms of files being uploaded and synced.
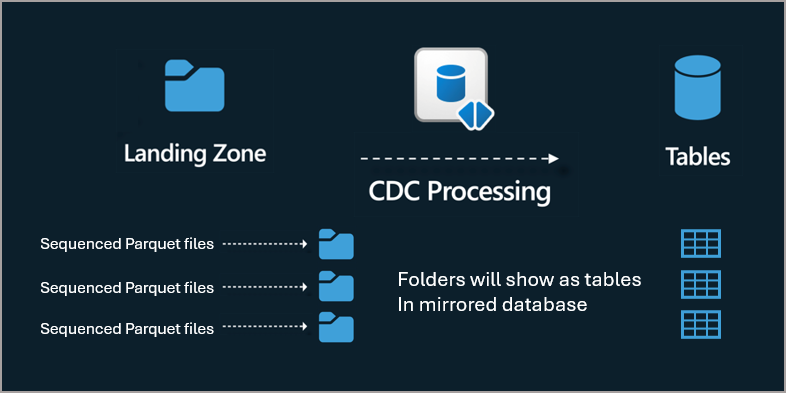
Walkthrough
The following steps outline a basic demonstration of how Open Mirroring operates:
Create a Mirroring Database
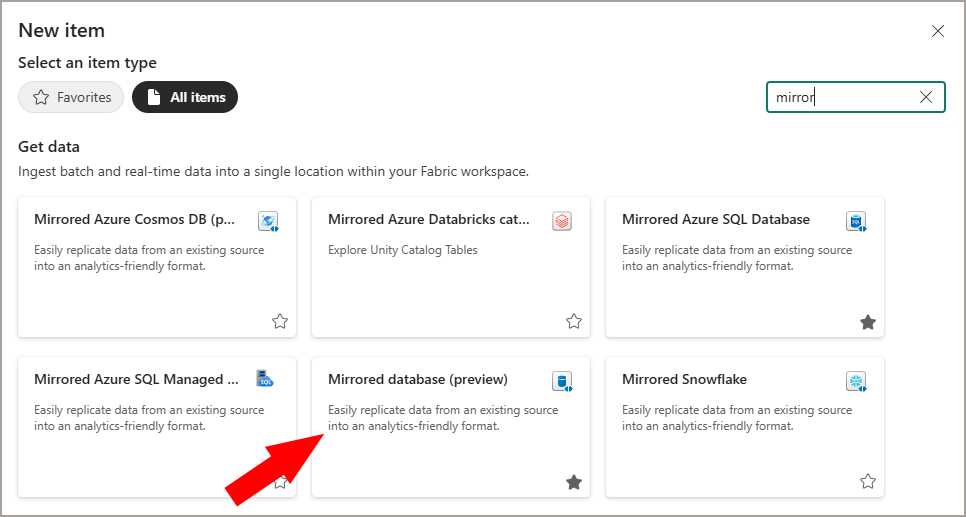
Within Fabric, create a new item and select the mirroring database option. For this demonstration, the database will be named DE_SQL_MIRROR_SOURCE.
- Login to Fabric and browse to a workspace that is allocated to a Fabric Capacity
- Click + New Item and search for Mirrored Database then click on the item to create
- Enter a name E.G DE_SQL_MIRROR_SOURCE and click Create
The Mirrored Database will provision, this should only take a few seconds to 1 minute to create. Pay particular attention to the Landing Zone URL as this is where we must create folders and load data to.

Create Folder & Upload Metadata
A _metadata.json file is required in each folder to which data will be pushed. This file specifies the key column (or columns) that form a unique key for the data, this is required to enable Update and Delete operations in the Mirrored Database. You can either download an example from GitHub here or create it from scratch:
{
"keyColumns": ["EmployeeID"]
}
To create the folder and upload files, I’m using Azure Storage Explorer.
- Open Azure Storage Explorer and open the Connect Dialog
- Specify ADLS Gen2 container or directory and enter the Landing Zone URL.
- Click + New Folder and enter source_employees as the folder name.
- Upload the _metadata.json file to this new folder
If you switch back to Fabric and in the Mirrored Database, click Refresh under the Monitor Replication section, you should see the folder appearing as a new table.
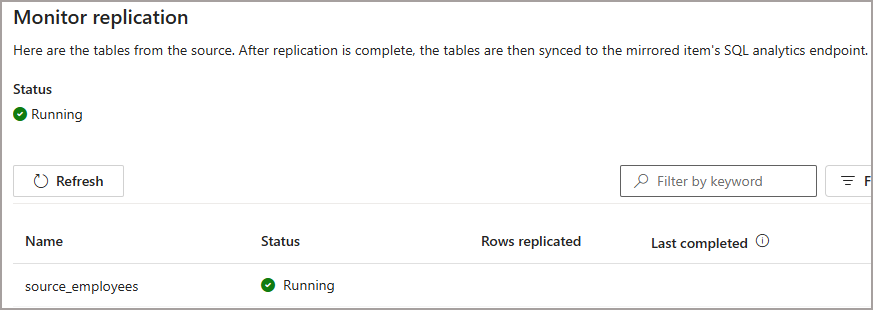
Upload Data
Please note the following:
- File Naming Conventions: Files must follow a specific naming pattern with leading zeros and sequential numbering (e.g., 00000000000000000001.parquet, 00000000000000000002.parquet). This ensures that the mirroring process can correctly identify and process the files in order.
- Data Format: The data files must be in Parquet format, and they should include a __rowmarker__ column to specify the action (insert, update, delete) for each row.
- 0 = INSERT
- 1 = UPDATE
- 2 = DELETE
- 3 = UPSERT
For this demo I have created 3 separate files to show the Insert, Update, and Delete operations in isolation. However, you are able to mix the row marker types in the same file. You can download the files from GitHub here.
Upload Data – Initial Load
Upload the file 00000000000000000001.parquet to the new folder. This file contains 3 rows with the __rowmarker__ column set to 0. This action will insert new rows into the mirroring database. After a few seconds the mirroring status should show 3 rows.
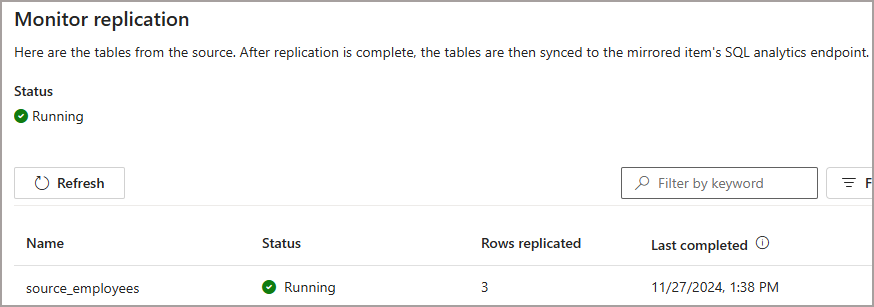
We can then query the SQL Endpoint using T-SQL and see the 3 rows. We don;t see the rowmarker column from the source data as that’s metadata for the mirroring process.
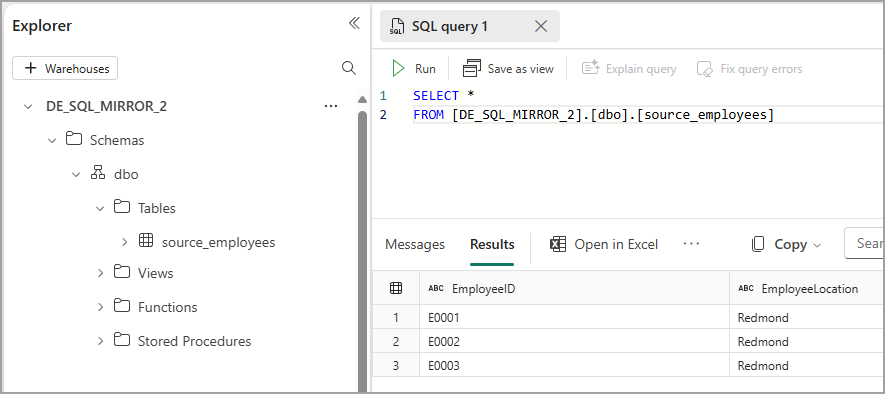
Upload Data – UPDATE & DELETE
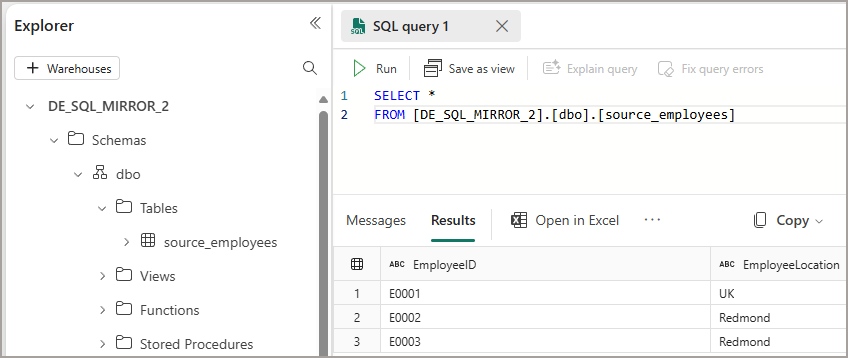
Upload the file 00000000000000000002.parquet to the new folder. This file contains 1 row with the __rowmarker__ column set to 1. This action will update rows into the mirroring database. After a few seconds the mirroring status should show 4 rows. If we query the data using the SQL Endpoint, we’ll see the update reflected.
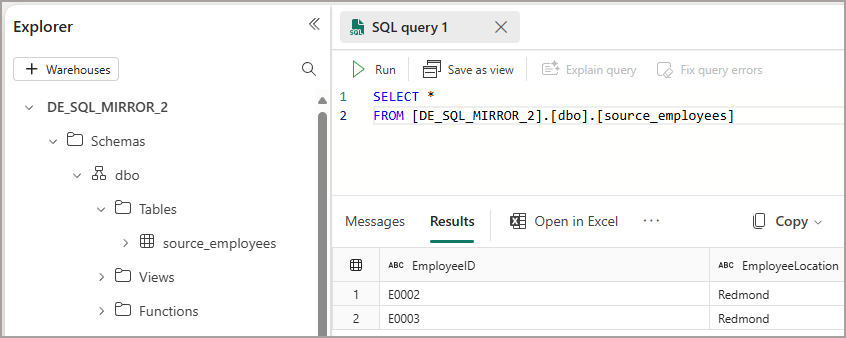
Finally, upload the file 00000000000000000003.parquet to the new folder. This file contains 1 row with the __rowmarker__ column set to 2. This action will delete rows into the mirroring database. After a few seconds the mirroring status should show 5 rows. If we query the data using the SQL Endpoint, we’ll see the delete reflected, and now only 2 employee records remain.
Monitoring
After uploading the files, the mirroring status can be monitored within the Fabric Mirroring database. The monitoring will indicate the number of rows replicated and any warnings. T-SQL can then be used to query the mirrored data. I hope that more fine-grained monitoring will be in place soon so show each load that has been applied including the file names, this would help to match exported rows from source systems to
Conclusion
I like Open Mirroring and believe it’s a great way to process data within Fabric without setting up additional workloads like notebooks/pipelines etc to ingest and process the data. You could write any process you want to extract data from any system and save it to the required format with the relevant metadata and Fabric can handle the rest.
References
For more detailed information, refer to the official documentation on Open Mirroring. There is also a great video series by Mark Pryce-Maher on YouTube.



